 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Tooth Mesh Segmentation with Simplified Mesh Cell Representation
Jan 25, 2023



Manual tooth segmentation of 3D tooth meshes is tedious and there is variations among dentists. %Manual tooth annotation of 3D tooth meshes is a tedious task. Several deep learning based methods have been proposed to perform automatic tooth mesh segmentation. Many of the proposed tooth mesh segmentation algorithms summarize the mesh cell as - the cell center or barycenter, the normal at barycenter, the cell vertices and the normals at the cell vertices. Summarizing of the mesh cell/triangle in this manner imposes an implicit structural constraint and makes it difficult to work with multiple resolutions which is done in many point cloud based deep learning algorithms. We propose a novel segmentation method which utilizes only the barycenter and the normal at the barycenter information of the mesh cell and yet achieves competitive performance. We are the first to demonstrate that it is possible to relax the implicit structural constraint and yet achieve superior segmentation performance
Automatic Tooth Segmentation from 3D Dental Model using Deep Learning: A Quantitative Analysis of what can be learnt from a Single 3D Dental Model
Sep 16, 2022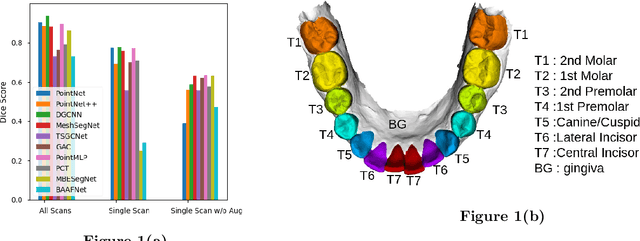

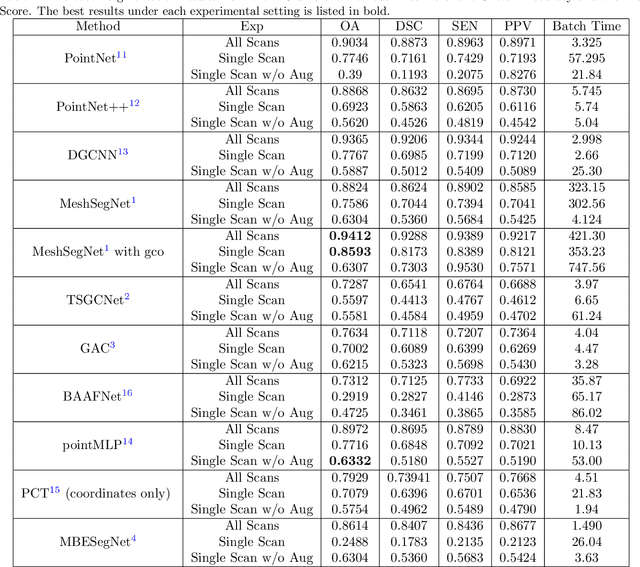
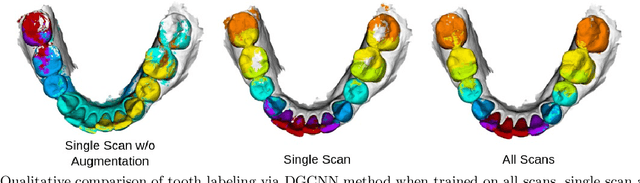
3D tooth segmentation is an important task for digital orthodontics. Several Deep Learning methods have been proposed for automatic tooth segmentation from 3D dental models or intraoral scans. These methods require annotated 3D intraoral scans. Manually annotating 3D intraoral scans is a laborious task. One approach is to devise self-supervision methods to reduce the manual labeling effort. Compared to other types of point cloud data like scene point cloud or shape point cloud data, 3D tooth point cloud data has a very regular structure and a strong shape prior. We look at how much representative information can be learnt from a single 3D intraoral scan. We evaluate this quantitatively with the help of ten different methods of which six are generic point cloud segmentation methods whereas the other four are tooth segmentation specific methods. Surprisingly, we find that with a single 3D intraoral scan training, the Dice score can be as high as 0.86 whereas the full training set gives Dice score of 0.94. We conclude that the segmentation methods can learn a great deal of information from a single 3D tooth point cloud scan under suitable conditions e.g. data augmentation. We are the first to quantitatively evaluate and demonstrate the representation learning capability of Deep Learning methods from a single 3D intraoral scan. This can enable building self-supervision methods for tooth segmentation under extreme data limitation scenario by leveraging the available data to the fullest possible extent.