 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoFunFlow-3D: A Physics-Guided Generative Flow Matching Framework for High-Fidelity 3D Aerodynamic Inference over Complex Geometries
Apr 25, 2026Deep generative models and neural operators have demonstrated significant potential for 3D aerodynamic inference. However, they often face inherent challenges in maintaining physical consistency and preserving high-frequency features, primarily due to spectral bias and gradient conflicts within the governing equations. To address these issues, we propose GeoFunFlow-3D, a physics-guided generative flow matching framework. Temporally, we utilize optimal transport theory to build the generation path, ensuring stable training dynamics. Spectrally, we introduce a high-order discrete engine without automatic differentiation (No-AD) to reduce gradient stiffness. Spatially, a topology-aware super-resolution module (SATO) is employed to rigorously enforce physical laws in localized regions such as shock waves. We evaluated our framework on complex industrial datasets. On the BlendedNet dataset, the model successfully avoids mode collapse even under sparse data conditions. For the NASA Rotor37 test, it accurately captures 3D detached shock structures. Compared to conventional operators, GeoFunFlow-3D significantly improves accuracy, reducing the pressure field error (RRMSE) to 0.0215 while maintaining competitive inference efficiency. Ultimately, this work provides a reliable, geometry-driven approach for generating high-dimensional fluid fields.
Attribute reduction algorithm of rough sets based on spatial optimization
May 15, 2024Rough set is one of the important methods for rule acquisition and attribute reduction. The current goal of rough set attribute reduction focuses more on minimizing the number of reduced attributes, but ignores the spatial similarity between reduced and decision attributes, which may lead to problems such as increased number of rules and limited generality. In this paper, a rough set attribute reduction algorithm based on spatial optimization is proposed. By introducing the concept of spatial similarity, to find the reduction with the highest spatial similarity, so that the spatial similarity between reduction and decision attributes is higher, and more concise and widespread rules are obtained. In addition, a comparative experiment with the traditional rough set attribute reduction algorithms is designed to prove the effectiveness of the rough set attribute reduction algorithm based on spatial optimization, which has made significant improvements on many datasets.
A new distance measurement and its application in K-Means Algorithm
Jun 10, 2022
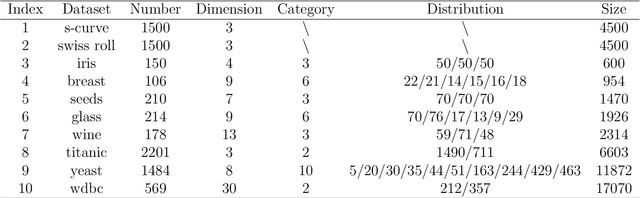

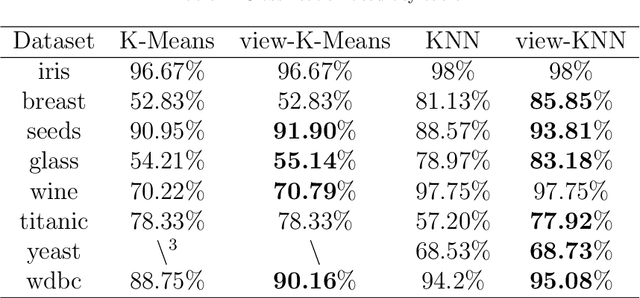
K-Means clustering algorithm is one of the most commonly used clustering algorithms because of its simplicity and efficiency. K-Means clustering algorithm based on Euclidean distance only pays attention to the linear distance between samples, but ignores the overall distribution structure of the dataset (i.e. the fluid structure of dataset). Since it is difficult to describe the internal structure of two data points by Euclidean distance in high-dimensional data space, we propose a new distance measurement, namely, view-distance, and apply it to the K-Means algorithm. On the classical manifold learning datasets, S-curve and Swiss roll datasets, not only this new distance can cluster the data according to the structure of the data itself, but also the boundaries between categories are neat dividing lines. Moreover, we also tested the classification accuracy and clustering effect of the K-Means algorithm based on view-distance on some real-world datasets. The experimental results show that, on most datasets, the K-Means algorithm based on view-distance has a certain degree of improvement in classification accuracy and clustering effect.