 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion 3-to-4: 3D Motion Reconstruction for 4D Synthesis
Jan 20, 2026We present Motion 3-to-4, a feed-forward framework for synthesising high-quality 4D dynamic objects from a single monocular video and an optional 3D reference mesh. While recent advances have significantly improved 2D, video, and 3D content generation, 4D synthesis remains difficult due to limited training data and the inherent ambiguity of recovering geometry and motion from a monocular viewpoint. Motion 3-to-4 addresses these challenges by decomposing 4D synthesis into static 3D shape generation and motion reconstruction. Using a canonical reference mesh, our model learns a compact motion latent representation and predicts per-frame vertex trajectories to recover complete, temporally coherent geometry. A scalable frame-wise transformer further enables robustness to varying sequence lengths. Evaluations on both standard benchmarks and a new dataset with accurate ground-truth geometry show that Motion 3-to-4 delivers superior fidelity and spatial consistency compared to prior work. Project page is available at https://motion3-to-4.github.io/.
PGAHum: Prior-Guided Geometry and Appearance Learning for High-Fidelity Animatable Human Reconstruction
Apr 22, 2024
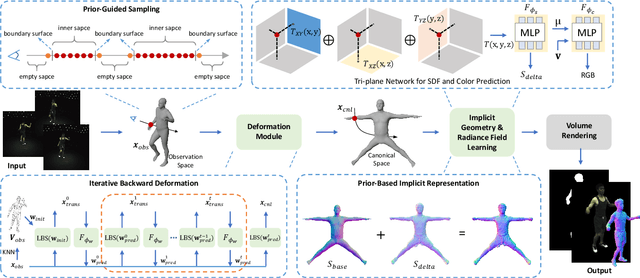


Recent techniques on implicit geometry representation learning and neural rendering have shown promising results for 3D clothed human reconstruction from sparse video inputs. However, it is still challenging to reconstruct detailed surface geometry and even more difficult to synthesize photorealistic novel views with animated human poses. In this work, we introduce PGAHum, a prior-guided geometry and appearance learning framework for high-fidelity animatable human reconstruction. We thoroughly exploit 3D human priors in three key modules of PGAHum to achieve high-quality geometry reconstruction with intricate details and photorealistic view synthesis on unseen poses. First, a prior-based implicit geometry representation of 3D human, which contains a delta SDF predicted by a tri-plane network and a base SDF derived from the prior SMPL model, is proposed to model the surface details and the body shape in a disentangled manner. Second, we introduce a novel prior-guided sampling strategy that fully leverages the prior information of the human pose and body to sample the query points within or near the body surface. By avoiding unnecessary learning in the empty 3D space, the neural rendering can recover more appearance details. Last, we propose a novel iterative backward deformation strategy to progressively find the correspondence for the query point in observation space. A skinning weights prediction model is learned based on the prior provided by the SMPL model to achieve the iterative backward LBS deformation. Extensive quantitative and qualitative comparisons on various datasets are conducted and the results demonstrate the superiority of our framework. Ablation studies also verify the effectiveness of each scheme for geometry and appearance learning.