 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeM-VG: Towards Generalized Multi-image Visual Grounding with Multimodal Large Language Models
Jan 08, 2026Multimodal Large Language Models (MLLMs) have demonstrated impressive progress in single-image grounding and general multi-image understanding. Recently, some methods begin to address multi-image grounding. However, they are constrained by single-target localization and limited types of practical tasks, due to the lack of unified modeling for generalized grounding tasks. Therefore, we propose GeM-VG, an MLLM capable of Generalized Multi-image Visual Grounding. To support this, we systematically categorize and organize existing multi-image grounding tasks according to their reliance of cross-image cues and reasoning, and introduce the MG-Data-240K dataset, addressing the limitations of existing datasets regarding target quantity and image relation. To tackle the challenges of robustly handling diverse multi-image grounding tasks, we further propose a hybrid reinforcement finetuning strategy that integrates chain-of-thought (CoT) reasoning and direct answering, considering their complementary strengths. This strategy adopts an R1-like algorithm guided by a carefully designed rule-based reward, effectively enhancing the model's overall perception and reasoning capabilities. Extensive experiments demonstrate the superior generalized grounding capabilities of our model. For multi-image grounding, it outperforms the previous leading MLLMs by 2.0% and 9.7% on MIG-Bench and MC-Bench, respectively. In single-image grounding, it achieves a 9.1% improvement over the base model on ODINW. Furthermore, our model retains strong capabilities in general multi-image understanding.
Understand, Think, and Answer: Advancing Visual Reasoning with Large Multimodal Models
May 27, 2025Large Multimodal Models (LMMs) have recently demonstrated remarkable visual understanding performance on both vision-language and vision-centric tasks. However, they often fall short in integrating advanced, task-specific capabilities for compositional reasoning, which hinders their progress toward truly competent general vision models. To address this, we present a unified visual reasoning mechanism that enables LMMs to solve complicated compositional problems by leveraging their intrinsic capabilities (e.g. grounding and visual understanding capabilities). Different from the previous shortcut learning mechanism, our approach introduces a human-like understanding-thinking-answering process, allowing the model to complete all steps in a single pass forwarding without the need for multiple inferences or external tools. This design bridges the gap between foundational visual capabilities and general question answering, encouraging LMMs to generate faithful and traceable responses for complex visual reasoning. Meanwhile, we curate 334K visual instruction samples covering both general scenes and text-rich scenes and involving multiple foundational visual capabilities. Our trained model, Griffon-R, has the ability of end-to-end automatic understanding, self-thinking, and reasoning answers. Comprehensive experiments show that Griffon-R not only achieves advancing performance on complex visual reasoning benchmarks including VSR and CLEVR, but also enhances multimodal capabilities across various benchmarks like MMBench and ScienceQA. Data, models, and codes will be release at https://github.com/jefferyZhan/Griffon/tree/master/Griffon-R soon.
Griffon-G: Bridging Vision-Language and Vision-Centric Tasks via Large Multimodal Models
Oct 21, 2024



Large Multimodal Models (LMMs) have achieved significant breakthroughs in various vision-language and vision-centric tasks based on auto-regressive modeling. However, these models typically focus on either vision-centric tasks, such as visual grounding and region description, or vision-language tasks, like image caption and multi-scenario VQAs. None of the LMMs have yet comprehensively unified both types of tasks within a single model, as seen in Large Language Models in the natural language processing field. Furthermore, even with abundant multi-task instruction-following data, directly stacking these data for universal capabilities extension remains challenging. To address these issues, we introduce a novel multi-dimension curated and consolidated multimodal dataset, named CCMD-8M, which overcomes the data barriers of unifying vision-centric and vision-language tasks through multi-level data curation and multi-task consolidation. More importantly, we present Griffon-G, a general large multimodal model that addresses both vision-centric and vision-language tasks within a single end-to-end paradigm. Griffon-G resolves the training collapse issue encountered during the joint optimization of these tasks, achieving better training efficiency. Evaluations across multimodal benchmarks, general Visual Question Answering (VQA) tasks, scene text-centric VQA tasks, document-related VQA tasks, Referring Expression Comprehension, and object detection demonstrate that Griffon-G surpasses the advanced LMMs and achieves expert-level performance in complicated vision-centric tasks.
Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
Mar 14, 2024


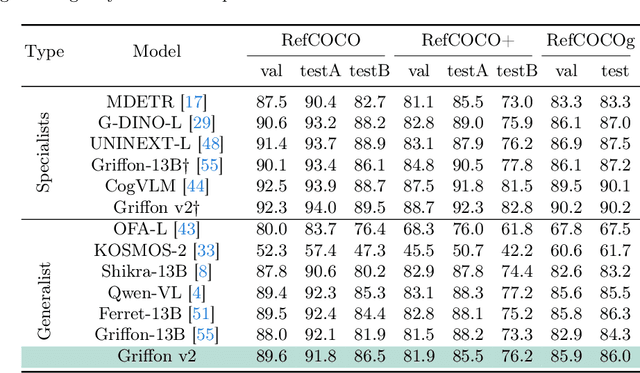
Large Vision Language Models have achieved fine-grained object perception, but the limitation of image resolution remains a significant obstacle to surpass the performance of task-specific experts in complex and dense scenarios. Such limitation further restricts the model's potential to achieve nuanced visual and language referring in domains such as GUI Agents, Counting and \etc. To address this issue, we introduce a unified high-resolution generalist model, Griffon v2, enabling flexible object referring with visual and textual prompts. To efficiently scaling up image resolution, we design a simple and lightweight down-sampling projector to overcome the input tokens constraint in Large Language Models. This design inherently preserves the complete contexts and fine details, and significantly improves multimodal perception ability especially for small objects. Building upon this, we further equip the model with visual-language co-referring capabilities through a plug-and-play visual tokenizer. It enables user-friendly interaction with flexible target images, free-form texts and even coordinates. Experiments demonstrate that Griffon v2 can localize any objects of interest with visual and textual referring, achieve state-of-the-art performance on REC, phrase grounding, and REG tasks, and outperform expert models in object detection and object counting. Data, codes and models will be released at https://github.com/jefferyZhan/Griffon.