 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Topology in Interactomic Network: From Transcriptome to Antiaddiction Drug Repurposing
Dec 03, 2023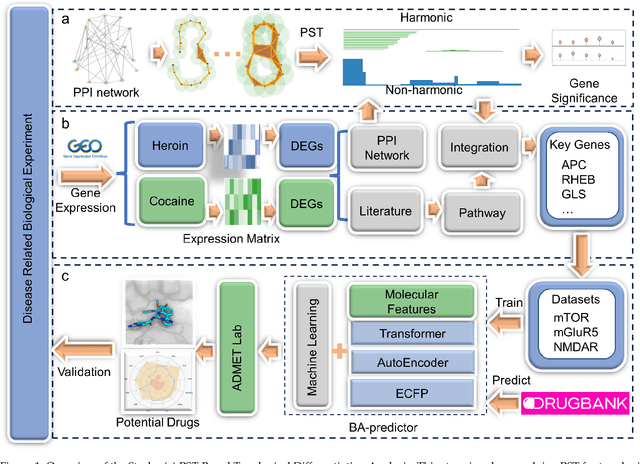
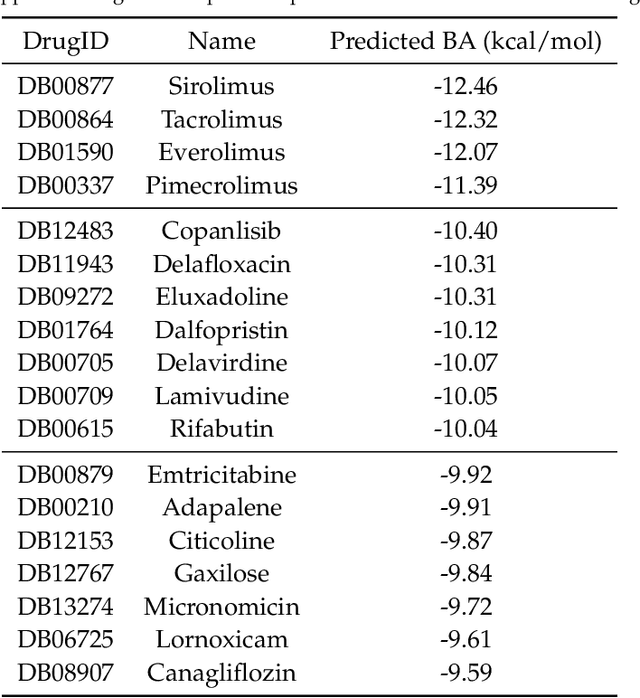
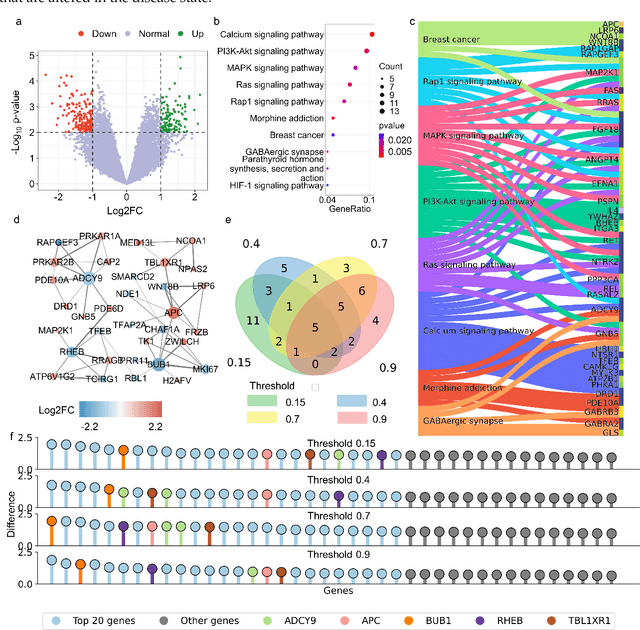
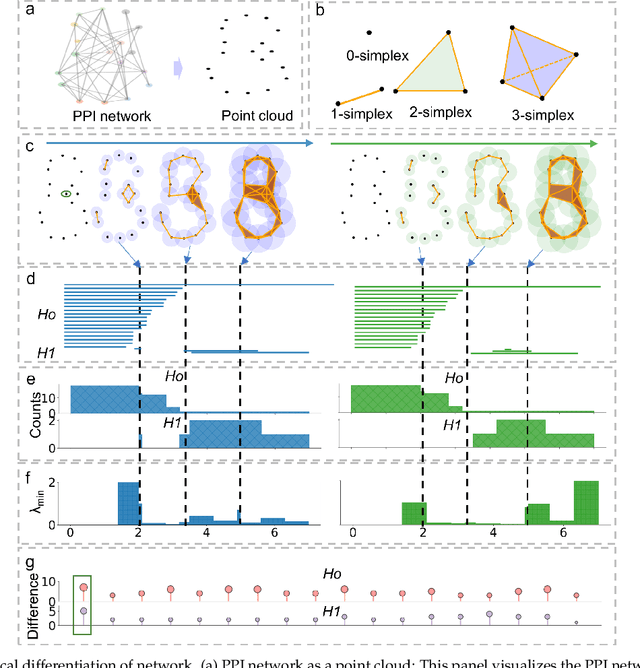
The escalating drug addiction crisis in the United States underscores the urgent need for innovative therapeutic strategies. This study embarked on an innovative and rigorous strategy to unearth potential drug repurposing candidates for opioid and cocaine addiction treatment, bridging the gap between transcriptomic data analysis and drug discovery. We initiated our approach by conducting differential gene expression analysis on addiction-related transcriptomic data to identify key genes. We propose a novel topological differentiation to identify key genes from a protein-protein interaction (PPI) network derived from DEGs. This method utilizes persistent Laplacians to accurately single out pivotal nodes within the network, conducting this analysis in a multiscale manner to ensure high reliability. Through rigorous literature validation, pathway analysis, and data-availability scrutiny, we identified three pivotal molecular targets, mTOR, mGluR5, and NMDAR, for drug repurposing from DrugBank. We crafted machine learning models employing two natural language processing (NLP)-based embeddings and a traditional 2D fingerprint, which demonstrated robust predictive ability in gauging binding affinities of DrugBank compounds to selected targets. Furthermore, we elucidated the interactions of promising drugs with the targets and evaluated their drug-likeness. This study delineates a multi-faceted and comprehensive analytical framework, amalgamating bioinformatics, topological data analysis and machine learning, for drug repurposing in addiction treatment, setting the stage for subsequent experimental validation. The versatility of the methods we developed allows for applications across a range of diseases and transcriptomic datasets.