 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Driven Kernel Flows: Label Rank Compression and Laplacian Spectral Filtering
Jan 01, 2026We present a theory of feature learning in wide L2-regularized networks showing that supervised learning is inherently compressive. We derive a kernel ODE that predicts a "water-filling" spectral evolution and prove that for any stable steady state, the kernel rank is bounded by the number of classes ($C$). We further demonstrate that SGD noise is similarly low-rank ($O(C)$), confining dynamics to the task-relevant subspace. This framework unifies the deterministic and stochastic views of alignment and contrasts the low-rank nature of supervised learning with the high-rank, expansive representations of self-supervision.
Video Summarization using Denoising Diffusion Probabilistic Model
Dec 12, 2024



Video summarization aims to eliminate visual redundancy while retaining key parts of video to construct concise and comprehensive synopses. Most existing methods use discriminative models to predict the importance scores of video frames. However, these methods are susceptible to annotation inconsistency caused by the inherent subjectivity of different annotators when annotating the same video. In this paper, we introduce a generative framework for video summarization that learns how to generate summaries from a probability distribution perspective, effectively reducing the interference of subjective annotation noise. Specifically, we propose a novel diffusion summarization method based on the Denoising Diffusion Probabilistic Model (DDPM), which learns the probability distribution of training data through noise prediction, and generates summaries by iterative denoising. Our method is more resistant to subjective annotation noise, and is less prone to overfitting the training data than discriminative methods, with strong generalization ability. Moreover, to facilitate training DDPM with limited data, we employ an unsupervised video summarization model to implement the earlier denoising process. Extensive experiments on various datasets (TVSum, SumMe, and FPVSum) demonstrate the effectiveness of our method.
How Vision-Language Tasks Benefit from Large Pre-trained Models: A Survey
Dec 11, 2024


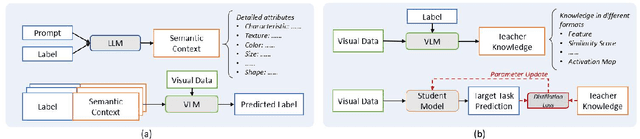
The exploration of various vision-language tasks, such as visual captioning, visual question answering, and visual commonsense reasoning, is an important area in artificial intelligence and continuously attracts the research community's attention. Despite the improvements in overall performance, classic challenges still exist in vision-language tasks and hinder the development of this area. In recent years, the rise of pre-trained models is driving the research on vision-language tasks. Thanks to the massive scale of training data and model parameters, pre-trained models have exhibited excellent performance in numerous downstream tasks. Inspired by the powerful capabilities of pre-trained models, new paradigms have emerged to solve the classic challenges. Such methods have become mainstream in current research with increasing attention and rapid advances. In this paper, we present a comprehensive overview of how vision-language tasks benefit from pre-trained models. First, we review several main challenges in vision-language tasks and discuss the limitations of previous solutions before the era of pre-training. Next, we summarize the recent advances in incorporating pre-trained models to address the challenges in vision-language tasks. Finally, we analyze the potential risks associated with the inherent limitations of pre-trained models and discuss possible solutions, attempting to provide future research directions.