 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaec: Similarity-Aware Embedding Compression in Recommendation Systems
Feb 26, 2019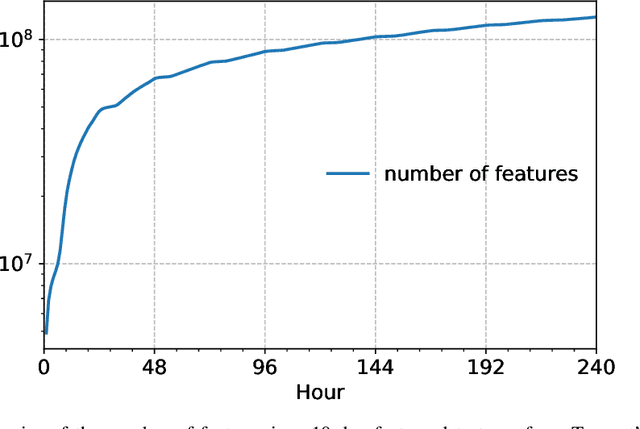
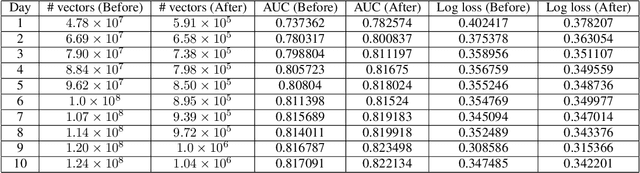
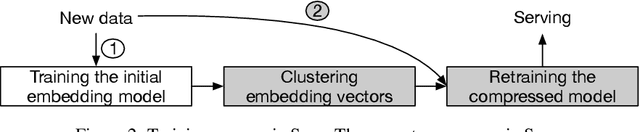
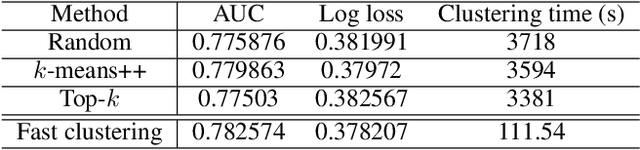
Production recommendation systems rely on embedding methods to represent various features. An impeding challenge in practice is that the large embedding matrix incurs substantial memory footprint in serving as the number of features grows over time. We propose a similarity-aware embedding matrix compression method called Saec to address this challenge. Saec clusters similar features within a field to reduce the embedding matrix size. Saec also adopts a fast clustering optimization based on feature frequency to drastically improve clustering time. We implement and evaluate Saec on Numerous, the production distributed machine learning system in Tencent, with 10-day worth of feature data from QQ mobile browser. Testbed experiments show that Saec reduces the number of embedding vectors by two orders of magnitude, compresses the embedding size by ~27x, and delivers the same AUC and log loss performance.