 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntensity-Spatial Dual Masked Autoencoder for Multi-Scale Feature Learning in Chest CT Segmentation
Nov 20, 2024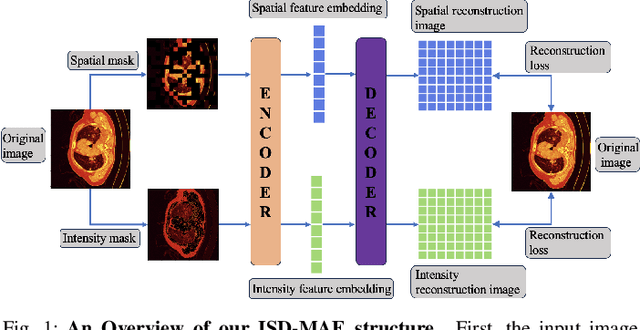
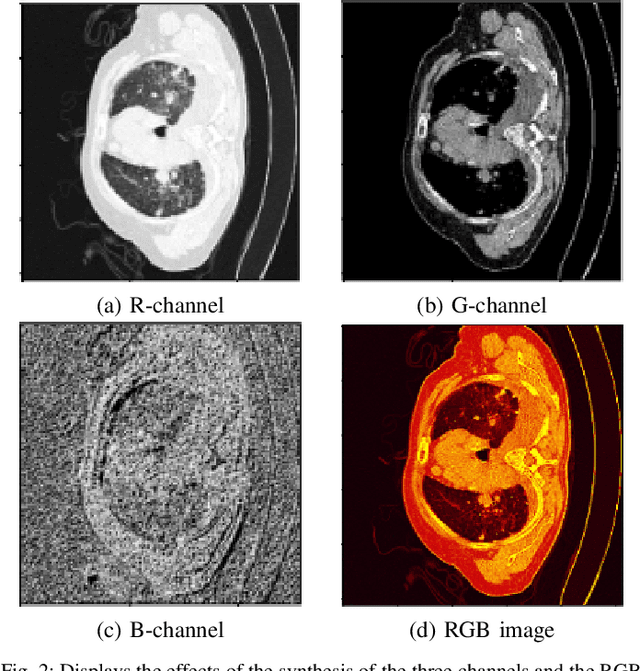
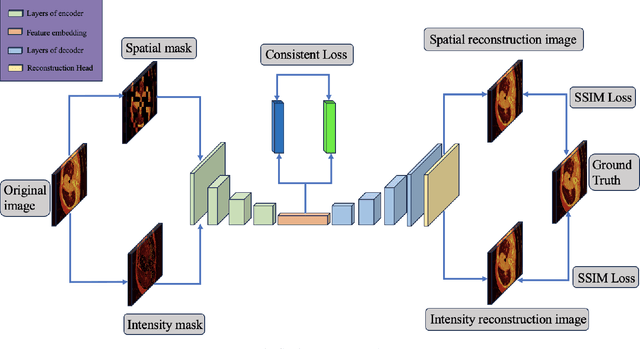
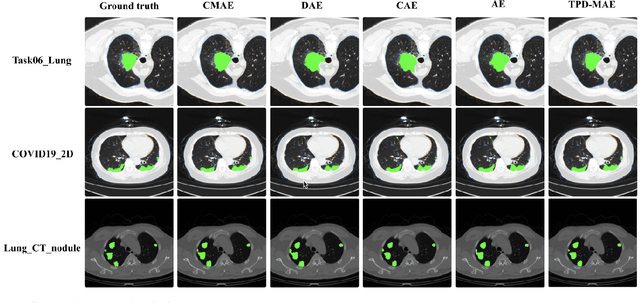
In the field of medical image segmentation, challenges such as indistinct lesion features, ambiguous boundaries,and multi-scale characteristics have long revailed. This paper proposes an improved method named Intensity-Spatial Dual Masked AutoEncoder (ISD-MAE). Based on the tissue-contrast semi-masked autoencoder, a Masked AutoEncoder (MAE) branch is introduced to perform intensity masking and spatial masking operations on chest CT images for multi-scale feature learning and segmentation tasks. The model utilizes a dual-branch structure and contrastive learning to enhance the ability to learn tissue features and boundary details. Experiments are conducted on multiple 2D and 3D datasets. The results show that ISD-MAE significantly outperforms other methods in 2D pneumonia and mediastinal tumor segmentation tasks. For example, the Dice score reaches 90.10% on the COVID19 LESION dataset, and the performance is relatively stable. However, there is still room for improvement on 3D datasets. In response to this, improvement directions are proposed, including optimizing the loss function, using enhanced 3D convolution blocks, and processing datasets from multiple perspectives.Our code is available at:https://github.com/prowontheus/ISD-MAE.
FusionU-Net: U-Net with Enhanced Skip Connection for Pathology Image Segmentation
Oct 17, 2023



In recent years, U-Net and its variants have been widely used in pathology image segmentation tasks. One of the key designs of U-Net is the use of skip connections between the encoder and decoder, which helps to recover detailed information after upsampling. While most variations of U-Net adopt the original skip connection design, there is semantic gap between the encoder and decoder that can negatively impact model performance. Therefore, it is important to reduce this semantic gap before conducting skip connection. To address this issue, we propose a new segmentation network called FusionU-Net, which is based on U-Net structure and incorporates a fusion module to exchange information between different skip connections to reduce semantic gaps. Unlike the other fusion modules in existing networks, ours is based on a two-round fusion design that fully considers the local relevance between adjacent encoder layer outputs and the need for bi-directional information exchange across multiple layers. We conducted extensive experiments on multiple pathology image datasets to evaluate our model and found that FusionU-Net achieves better performance compared to other competing methods. We argue our fusion module is more effective than the designs of existing networks, and it could be easily embedded into other networks to further enhance the model performance.