 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCELI: Controller-Embedded Language Model Interactions
Oct 18, 2024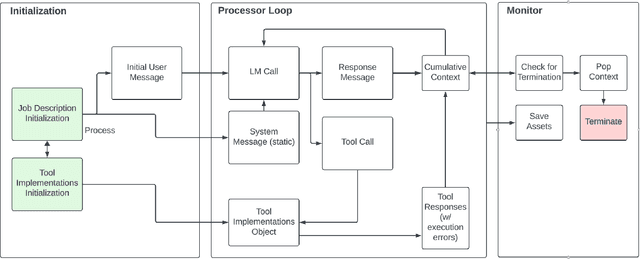

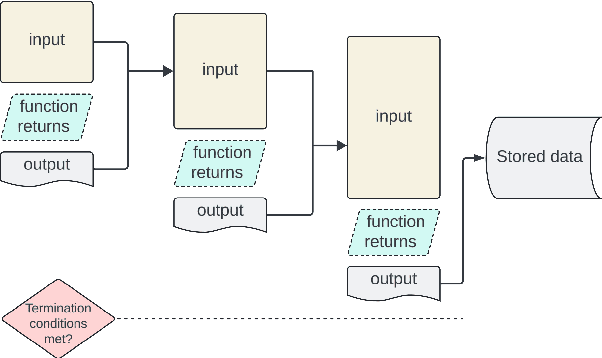
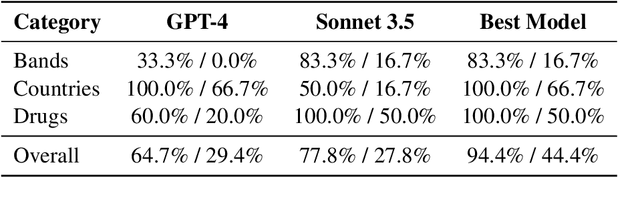
We introduce Controller-Embedded Language Model Interactions (CELI), a framework that integrates control logic directly within language model (LM) prompts, facilitating complex, multi-stage task execution. CELI addresses limitations of existing prompt engineering and workflow optimization techniques by embedding control logic directly within the operational context of language models, enabling dynamic adaptation to evolving task requirements. Our framework transfers control from the traditional programming execution environment to the LMs, allowing them to autonomously manage computational workflows while maintaining seamless interaction with external systems and functions. CELI supports arbitrary function calls with variable arguments, bridging the gap between LMs' adaptive reasoning capabilities and conventional software paradigms' structured control mechanisms. To evaluate CELI's versatility and effectiveness, we conducted case studies in two distinct domains: code generation (HumanEval benchmark) and multi-stage content generation (Wikipedia-style articles). The results demonstrate notable performance improvements across a range of domains. CELI achieved a 4.9 percentage point improvement over the best reported score of the baseline GPT-4 model on the HumanEval code generation benchmark. In multi-stage content generation, 94.4% of CELI-produced Wikipedia-style articles met or exceeded first draft quality when optimally configured, with 44.4% achieving high quality. These outcomes underscore CELI's potential for optimizing AI-driven workflows across diverse computational domains.
Improving accuracy of GPT-3/4 results on biomedical data using a retrieval-augmented language model
May 30, 2023


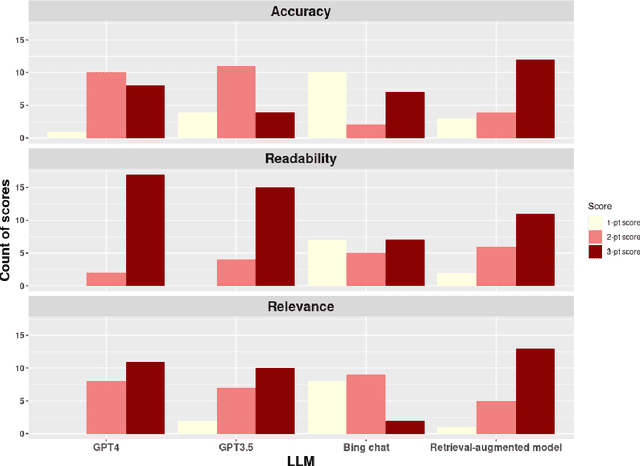
Large language models (LLMs) have made significant advancements in natural language processing (NLP). Broad corpora capture diverse patterns but can introduce irrelevance, while focused corpora enhance reliability by reducing misleading information. Training LLMs on focused corpora poses computational challenges. An alternative approach is to use a retrieval-augmentation (RetA) method tested in a specific domain. To evaluate LLM performance, OpenAI's GPT-3, GPT-4, Bing's Prometheus, and a custom RetA model were compared using 19 questions on diffuse large B-cell lymphoma (DLBCL) disease. Eight independent reviewers assessed responses based on accuracy, relevance, and readability (rated 1-3). The RetA model performed best in accuracy (12/19 3-point scores, total=47) and relevance (13/19, 50), followed by GPT-4 (8/19, 43; 11/19, 49). GPT-4 received the highest readability scores (17/19, 55), followed by GPT-3 (15/19, 53) and the RetA model (11/19, 47). Prometheus underperformed in accuracy (34), relevance (32), and readability (38). Both GPT-3.5 and GPT-4 had more hallucinations in all 19 responses compared to the RetA model and Prometheus. Hallucinations were mostly associated with non-existent references or fabricated efficacy data. These findings suggest that RetA models, supplemented with domain-specific corpora, may outperform general-purpose LLMs in accuracy and relevance within specific domains. However, this evaluation was limited to specific questions and metrics and may not capture challenges in semantic search and other NLP tasks. Further research will explore different LLM architectures, RetA methodologies, and evaluation methods to assess strengths and limitations more comprehensively.