 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Moment Matching Network-based Random Modulation Post-filter for DNN-based Singing Voice Synthesis and Neural Double-tracking
Feb 09, 2019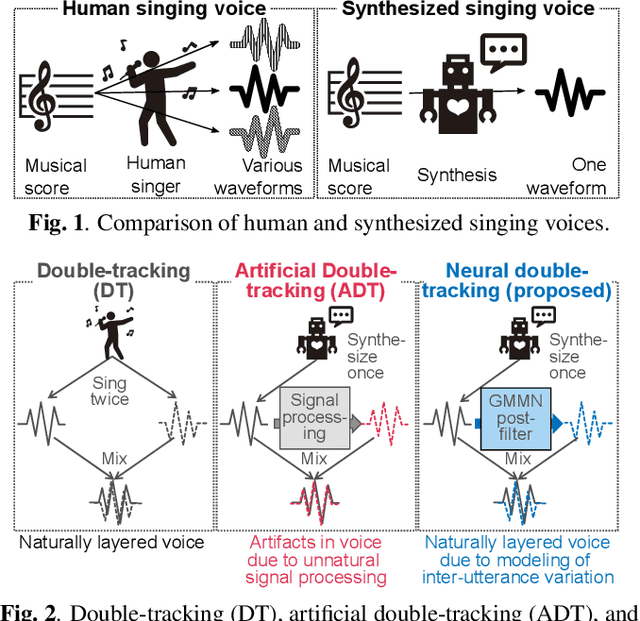
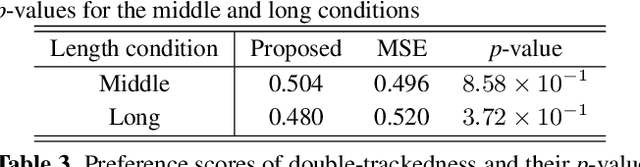
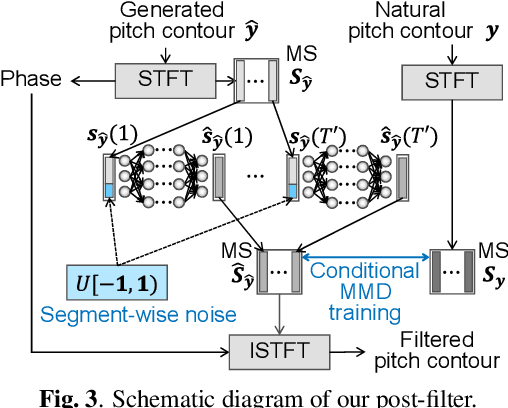
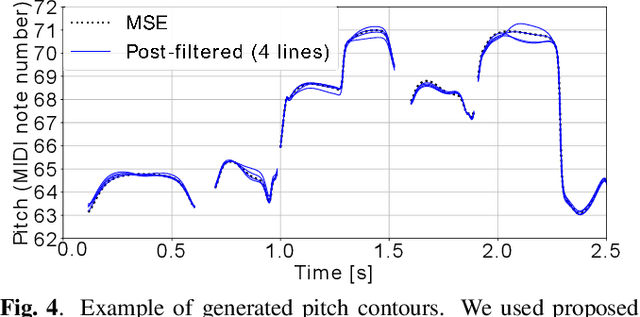
This paper proposes a generative moment matching network (GMMN)-based post-filter that provides inter-utterance pitch variation for deep neural network (DNN)-based singing voice synthesis. The natural pitch variation of a human singing voice leads to a richer musical experience and is used in double-tracking, a recording method in which two performances of the same phrase are recorded and mixed to create a richer, layered sound. However, singing voices synthesized using conventional DNN-based methods never vary because the synthesis process is deterministic and only one waveform is synthesized from one musical score. To address this problem, we use a GMMN to model the variation of the modulation spectrum of the pitch contour of natural singing voices and add a randomized inter-utterance variation to the pitch contour generated by conventional DNN-based singing voice synthesis. Experimental evaluations suggest that 1) our approach can provide perceptible inter-utterance pitch variation while preserving speech quality. We extend our approach to double-tracking, and the evaluation demonstrates that 2) GMMN-based neural double-tracking is perceptually closer to natural double-tracking than conventional signal processing-based artificial double-tracking is.