 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling BERT Models for Turkish Automatic Punctuation and Capitalization Correction
Dec 03, 2024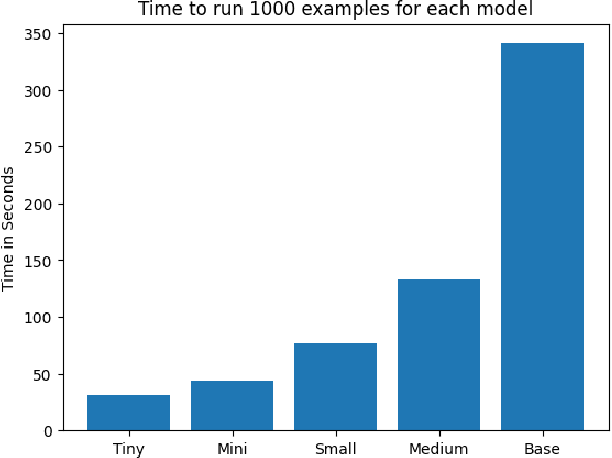
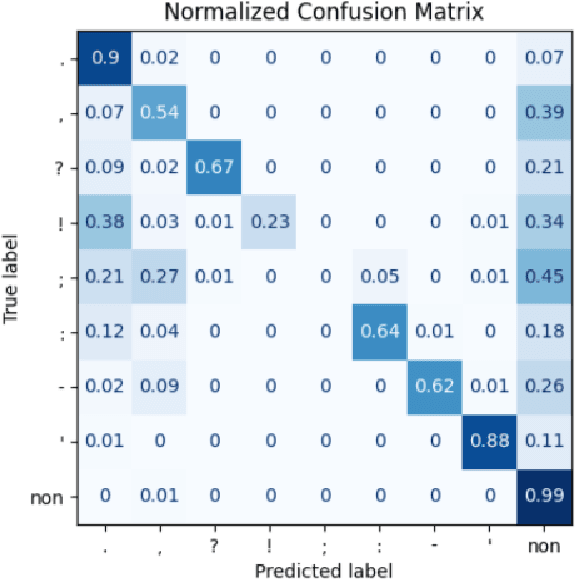
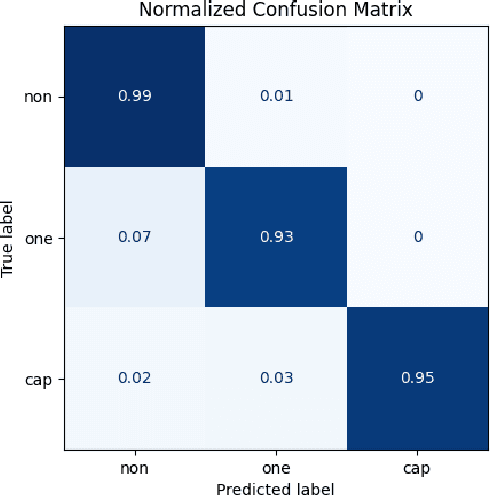
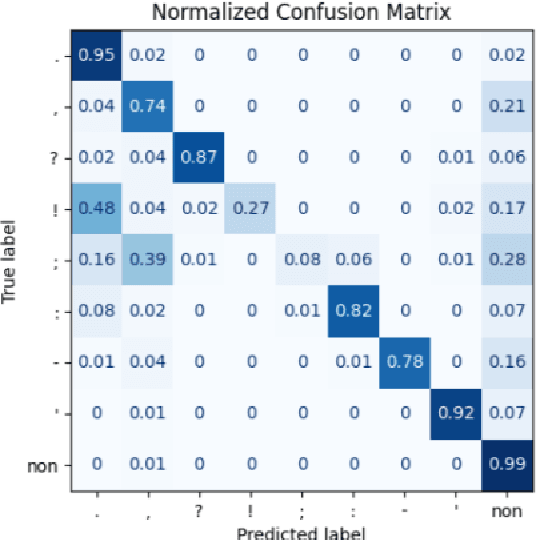
This paper investigates the effectiveness of BERT based models for automated punctuation and capitalization corrections in Turkish texts across five distinct model sizes. The models are designated as Tiny, Mini, Small, Medium, and Base. The design and capabilities of each model are tailored to address the specific challenges of the Turkish language, with a focus on optimizing performance while minimizing computational overhead. The study presents a systematic comparison of the performance metrics precision, recall, and F1 score of each model, offering insights into their applicability in diverse operational contexts. The results demonstrate a significant improvement in text readability and accuracy as model size increases, with the Base model achieving the highest correction precision. This research provides a comprehensive guide for selecting the appropriate model size based on specific user needs and computational resources, establishing a framework for deploying these models in real-world applications to enhance the quality of written Turkish.
* 2024 Innovations in Intelligent Systems and Applications Conference (ASYU)
Advancing NLP Models with Strategic Text Augmentation: A Comprehensive Study of Augmentation Methods and Curriculum Strategies
Feb 14, 2024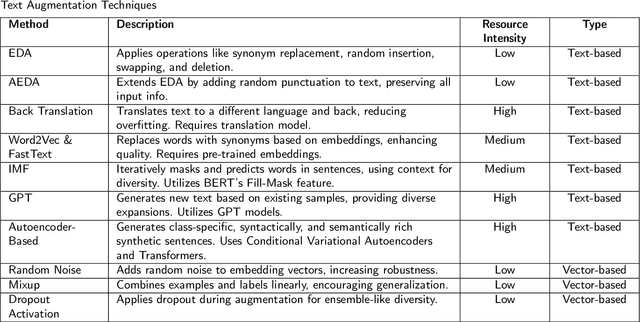
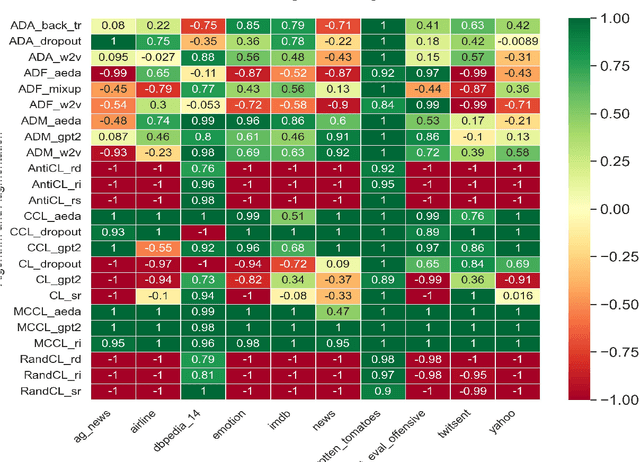


This study conducts a thorough evaluation of text augmentation techniques across a variety of datasets and natural language processing (NLP) tasks to address the lack of reliable, generalized evidence for these methods. It examines the effectiveness of these techniques in augmenting training sets to improve performance in tasks such as topic classification, sentiment analysis, and offensive language detection. The research emphasizes not only the augmentation methods, but also the strategic order in which real and augmented instances are introduced during training. A major contribution is the development and evaluation of Modified Cyclical Curriculum Learning (MCCL) for augmented datasets, which represents a novel approach in the field. Results show that specific augmentation methods, especially when integrated with MCCL, significantly outperform traditional training approaches in NLP model performance. These results underscore the need for careful selection of augmentation techniques and sequencing strategies to optimize the balance between speed and quality improvement in various NLP tasks. The study concludes that the use of augmentation methods, especially in conjunction with MCCL, leads to improved results in various classification tasks, providing a foundation for future advances in text augmentation strategies in NLP.
Investigating Semi-Supervised Learning Algorithms in Text Datasets
Jan 07, 2024Using large training datasets enhances the generalization capabilities of neural networks. Semi-supervised learning (SSL) is useful when there are few labeled data and a lot of unlabeled data. SSL methods that use data augmentation are most successful for image datasets. In contrast, texts do not have consistent augmentation methods as images. Consequently, methods that use augmentation are not as effective in text data as they are in image data. In this study, we compared SSL algorithms that do not require augmentation; these are self-training, co-training, tri-training, and tri-training with disagreement. In the experiments, we used 4 different text datasets for different tasks. We examined the algorithms from a variety of perspectives by asking experiment questions and suggested several improvements. Among the algorithms, tri-training with disagreement showed the closest performance to the Oracle; however, performance gap shows that new semi-supervised algorithms or improvements in existing methods are needed.
* Innovations in Intelligent Systems and Applications Conference (ASYU)
Iterative Mask Filling: An Effective Text Augmentation Method Using Masked Language Modeling
Jan 03, 2024Data augmentation is an effective technique for improving the performance of machine learning models. However, it has not been explored as extensively in natural language processing (NLP) as it has in computer vision. In this paper, we propose a novel text augmentation method that leverages the Fill-Mask feature of the transformer-based BERT model. Our method involves iteratively masking words in a sentence and replacing them with language model predictions. We have tested our proposed method on various NLP tasks and found it to be effective in many cases. Our results are presented along with a comparison to existing augmentation methods. Experimental results show that our proposed method significantly improves performance, especially on topic classification datasets.
* Published in International Conference on Advanced Engineering, Technology and Applications (ICAETA 2023). The final version is available online at https://link.springer.com/chapter/10.1007/978-3-031-50920-9_35
Developing and Evaluating Tiny to Medium-Sized Turkish BERT Models
Jul 26, 2023
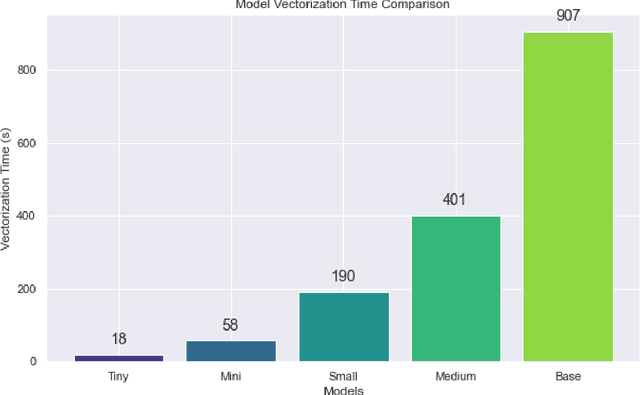
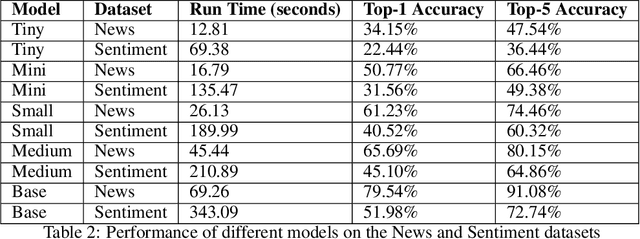
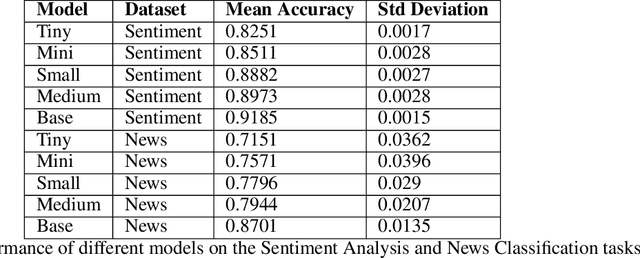
This study introduces and evaluates tiny, mini, small, and medium-sized uncased Turkish BERT models, aiming to bridge the research gap in less-resourced languages. We trained these models on a diverse dataset encompassing over 75GB of text from multiple sources and tested them on several tasks, including mask prediction, sentiment analysis, news classification, and, zero-shot classification. Despite their smaller size, our models exhibited robust performance, including zero-shot task, while ensuring computational efficiency and faster execution times. Our findings provide valuable insights into the development and application of smaller language models, especially in the context of the Turkish language.
A Robust Optimization Method for Label Noisy Datasets Based on Adaptive Threshold: Adaptive-k
Mar 26, 2022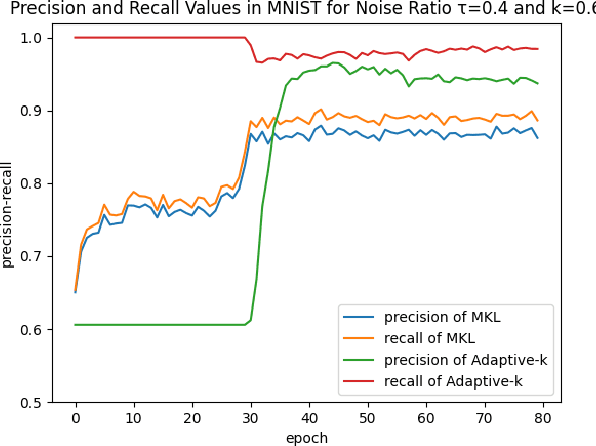
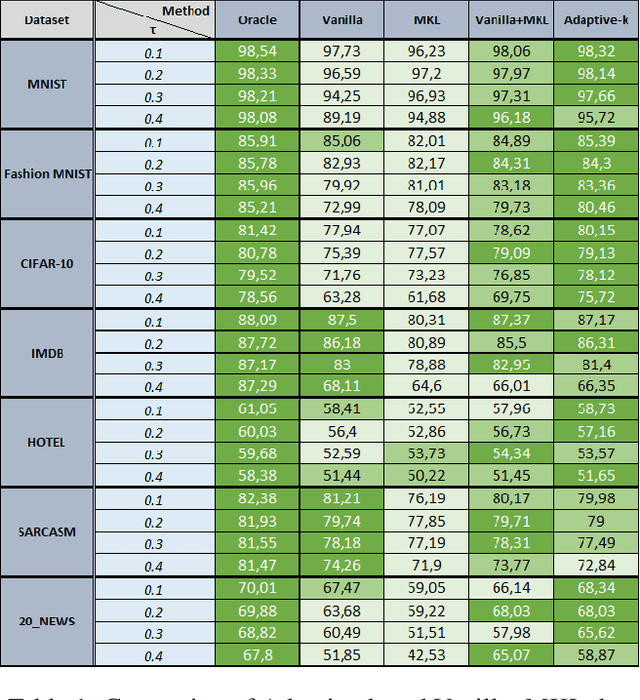
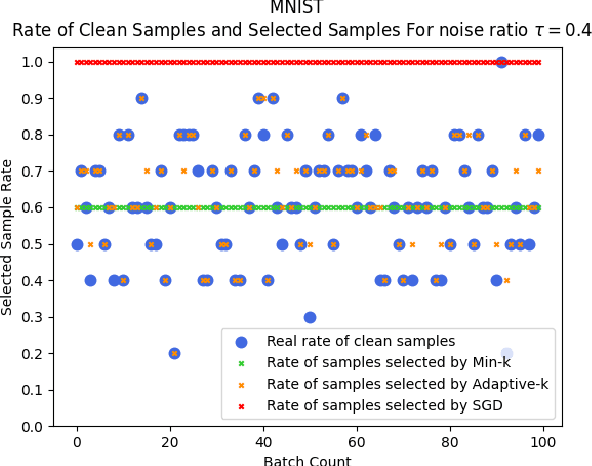
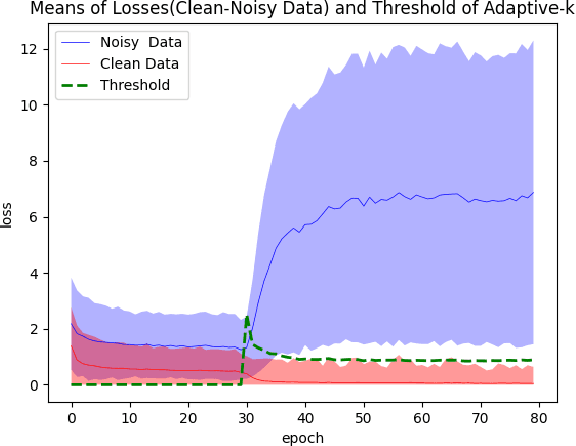
SGD does not produce robust results on datasets with label noise. Because the gradients calculated according to the losses of the noisy samples cause the optimization process to go in the wrong direction. In this paper, as an alternative to SGD, we recommend using samples with loss less than a threshold value determined during the optimization process, instead of using all samples in the mini-batch. Our proposed method, Adaptive-k, aims to exclude label noise samples from the optimization process and make the process robust. On noisy datasets, we found that using a threshold-based approach, such as Adaptive-k, produces better results than using all samples or a fixed number of low-loss samples in the mini-batch. Based on our theoretical analysis and experimental results, we show that the Adaptive-k method is closest to the performance of the oracle, in which noisy samples are entirely removed from the dataset. Adaptive-k is a simple but effective method. It does not require prior knowledge of the noise ratio of the dataset, does not require additional model training, and does not increase training time significantly. The code for Adaptive-k is available at https://github.com/enesdedeoglu-TR/Adaptive-k