 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Optimization Method for Label Noisy Datasets Based on Adaptive Threshold: Adaptive-k
Paper and Code
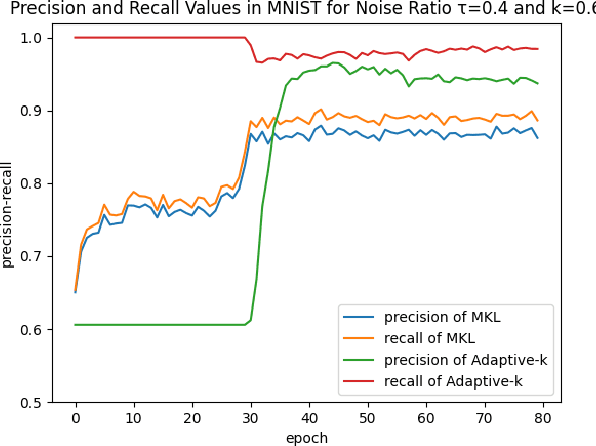
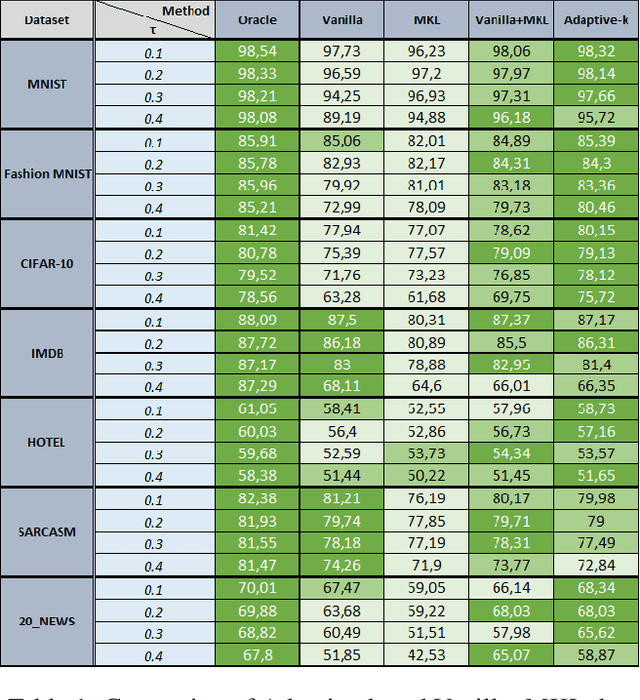
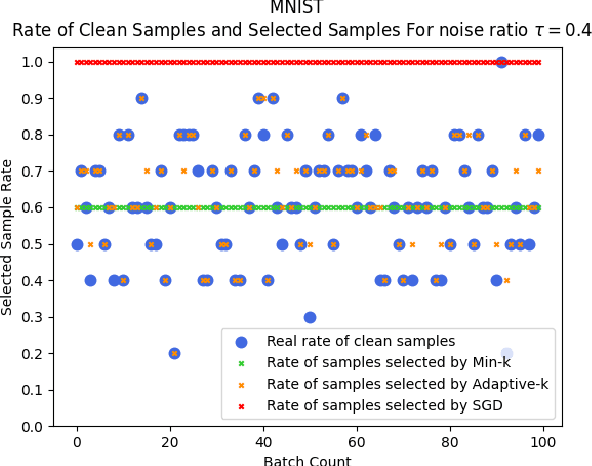
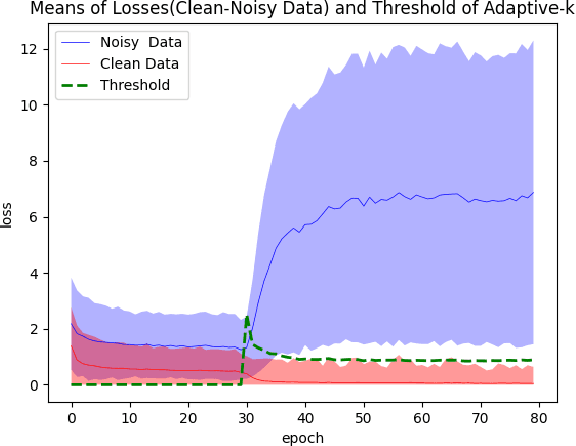
SGD does not produce robust results on datasets with label noise. Because the gradients calculated according to the losses of the noisy samples cause the optimization process to go in the wrong direction. In this paper, as an alternative to SGD, we recommend using samples with loss less than a threshold value determined during the optimization process, instead of using all samples in the mini-batch. Our proposed method, Adaptive-k, aims to exclude label noise samples from the optimization process and make the process robust. On noisy datasets, we found that using a threshold-based approach, such as Adaptive-k, produces better results than using all samples or a fixed number of low-loss samples in the mini-batch. Based on our theoretical analysis and experimental results, we show that the Adaptive-k method is closest to the performance of the oracle, in which noisy samples are entirely removed from the dataset. Adaptive-k is a simple but effective method. It does not require prior knowledge of the noise ratio of the dataset, does not require additional model training, and does not increase training time significantly. The code for Adaptive-k is available at https://github.com/enesdedeoglu-TR/Adaptive-k