Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping and Evaluating Tiny to Medium-Sized Turkish BERT Models
Jul 26, 2023
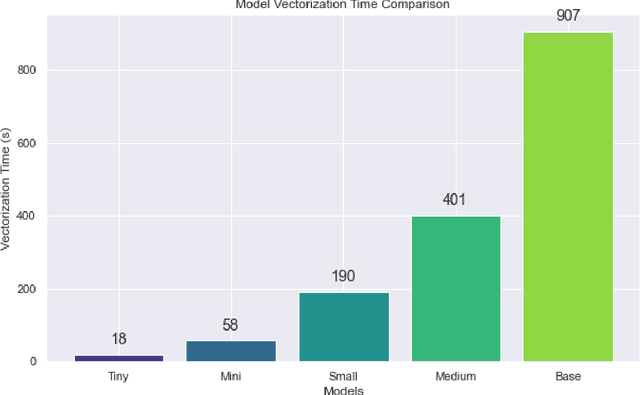
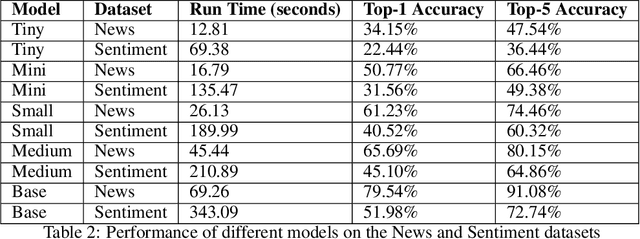
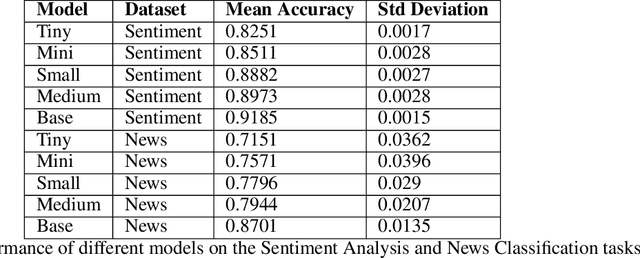
This study introduces and evaluates tiny, mini, small, and medium-sized uncased Turkish BERT models, aiming to bridge the research gap in less-resourced languages. We trained these models on a diverse dataset encompassing over 75GB of text from multiple sources and tested them on several tasks, including mask prediction, sentiment analysis, news classification, and, zero-shot classification. Despite their smaller size, our models exhibited robust performance, including zero-shot task, while ensuring computational efficiency and faster execution times. Our findings provide valuable insights into the development and application of smaller language models, especially in the context of the Turkish language.
Via