 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Efficient Adaptive Attention For Multiple Domain Learning
Oct 21, 2021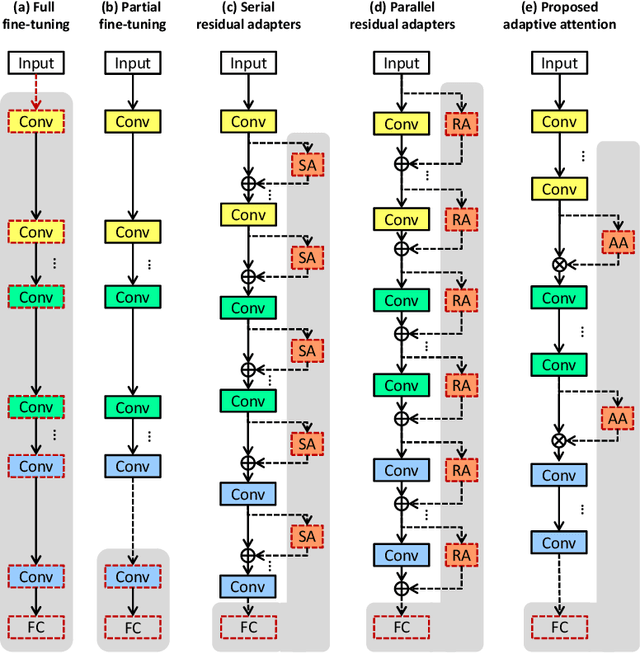
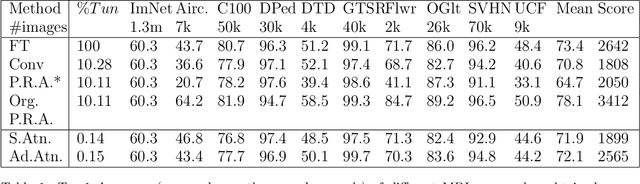


Training CNNs from scratch on new domains typically demands large numbers of labeled images and computations, which is not suitable for low-power hardware. One way to reduce these requirements is to modularize the CNN architecture and freeze the weights of the heavier modules, that is, the lower layers after pre-training. Recent studies have proposed alternative modular architectures and schemes that lead to a reduction in the number of trainable parameters needed to match the accuracy of fully fine-tuned CNNs on new domains. Our work suggests that a further reduction in the number of trainable parameters by an order of magnitude is possible. Furthermore, we propose that new modularization techniques for multiple domain learning should also be compared on other realistic metrics, such as the number of interconnections needed between the fixed and trainable modules, the number of training samples needed, the order of computations required and the robustness to partial mislabeling of the training data. On all of these criteria, the proposed architecture demonstrates advantages over or matches the current state-of-the-art.
Activation Functions: Do They Represent A Trade-Off Between Modular Nature of Neural Networks And Task Performance
Sep 16, 2020


Current research suggests that the key factors in designing neural network architectures involve choosing number of filters for every convolution layer, number of hidden neurons for every fully connected layer, dropout and pruning. The default activation function in most cases is the ReLU, as it has empirically shown faster training convergence. We explore whether ReLU is the best choice if one is aiming to desire better modularity structure within a neural network.