 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFragile Giants: Understanding the Susceptibility of Models to Subpopulation Attacks
Oct 11, 2024



As machine learning models become increasingly complex, concerns about their robustness and trustworthiness have become more pressing. A critical vulnerability of these models is data poisoning attacks, where adversaries deliberately alter training data to degrade model performance. One particularly stealthy form of these attacks is subpopulation poisoning, which targets distinct subgroups within a dataset while leaving overall performance largely intact. The ability of these attacks to generalize within subpopulations poses a significant risk in real-world settings, as they can be exploited to harm marginalized or underrepresented groups within the dataset. In this work, we investigate how model complexity influences susceptibility to subpopulation poisoning attacks. We introduce a theoretical framework that explains how overparameterized models, due to their large capacity, can inadvertently memorize and misclassify targeted subpopulations. To validate our theory, we conduct extensive experiments on large-scale image and text datasets using popular model architectures. Our results show a clear trend: models with more parameters are significantly more vulnerable to subpopulation poisoning. Moreover, we find that attacks on smaller, human-interpretable subgroups often go undetected by these models. These results highlight the need to develop defenses that specifically address subpopulation vulnerabilities.
RoFL: Attestable Robustness for Secure Federated Learning
Jul 19, 2021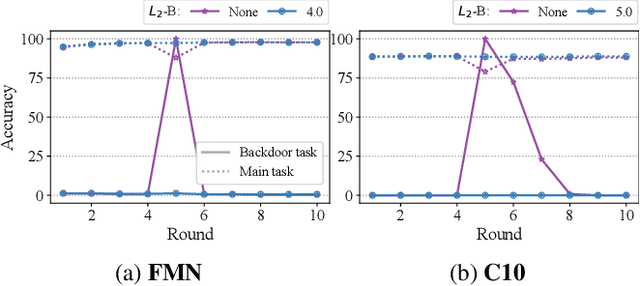

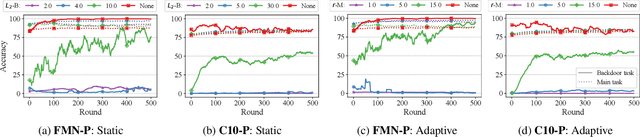
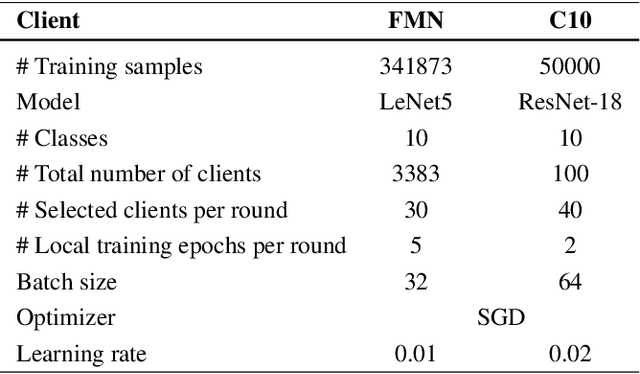
Federated Learning is an emerging decentralized machine learning paradigm that allows a large number of clients to train a joint model without the need to share their private data. Participants instead only share ephemeral updates necessary to train the model. To ensure the confidentiality of the client updates, Federated Learning systems employ secure aggregation; clients encrypt their gradient updates, and only the aggregated model is revealed to the server. Achieving this level of data protection, however, presents new challenges to the robustness of Federated Learning, i.e., the ability to tolerate failures and attacks. Unfortunately, in this setting, a malicious client can now easily exert influence on the model behavior without being detected. As Federated Learning is being deployed in practice in a range of sensitive applications, its robustness is growing in importance. In this paper, we take a step towards understanding and improving the robustness of secure Federated Learning. We start this paper with a systematic study that evaluates and analyzes existing attack vectors and discusses potential defenses and assesses their effectiveness. We then present RoFL, a secure Federated Learning system that improves robustness against malicious clients through input checks on the encrypted model updates. RoFL extends Federated Learning's secure aggregation protocol to allow expressing a variety of properties and constraints on model updates using zero-knowledge proofs. To enable RoFL to scale to typical Federated Learning settings, we introduce several ML and cryptographic optimizations specific to Federated Learning. We implement and evaluate a prototype of RoFL and show that realistic ML models can be trained in a reasonable time while improving robustness.