 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank-Learner: Orthogonal Ranking of Treatment Effects
Feb 03, 2026Many decision-making problems require ranking individuals by their treatment effects rather than estimating the exact effect magnitudes. Examples include prioritizing patients for preventive care interventions, or ranking customers by the expected incremental impact of an advertisement. Surprisingly, while causal effect estimation has received substantial attention in the literature, the problem of directly learning rankings of treatment effects has largely remained unexplored. In this paper, we introduce Rank-Learner, a novel two-stage learner that directly learns the ranking of treatment effects from observational data. We first show that naive approaches based on precise treatment effect estimation solve a harder problem than necessary for ranking, while our Rank-Learner optimizes a pairwise learning objective that recovers the true treatment effect ordering, without explicit CATE estimation. We further show that our Rank-Learner is Neyman-orthogonal and thus comes with strong theoretical guarantees, including robustness to estimation errors in the nuisance functions. In addition, our Rank-Learner is model-agnostic, and can be instantiated with arbitrary machine learning models (e.g., neural networks). We demonstrate the effectiveness of our method through extensive experiments where Rank-Learner consistently outperforms standard CATE estimators and non-orthogonal ranking methods. Overall, we provide practitioners with a new, orthogonal two-stage learner for ranking individuals by their treatment effects.
Personalized Treatment Effect Estimation from Unstructured Data
Jul 28, 2025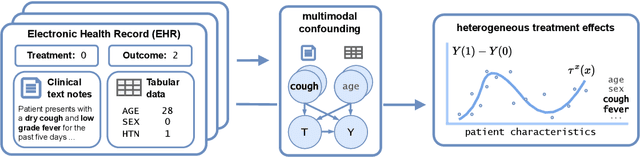

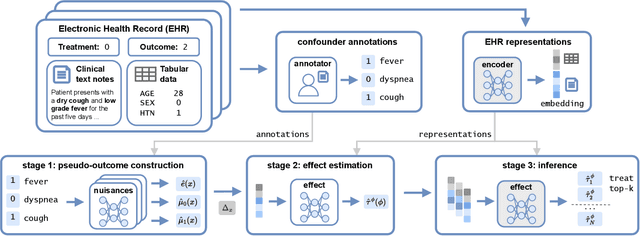
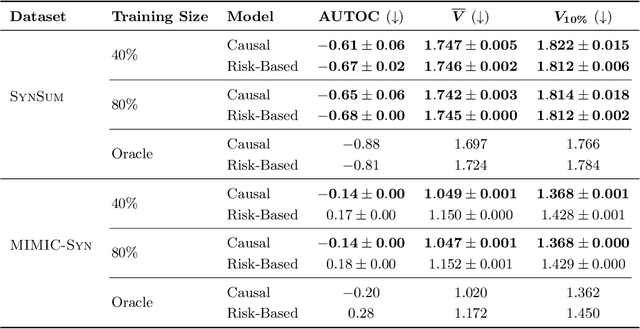
Existing methods for estimating personalized treatment effects typically rely on structured covariates, limiting their applicability to unstructured data. Yet, leveraging unstructured data for causal inference has considerable application potential, for instance in healthcare, where clinical notes or medical images are abundant. To this end, we first introduce an approximate 'plug-in' method trained directly on the neural representations of unstructured data. However, when these fail to capture all confounding information, the method may be subject to confounding bias. We therefore introduce two theoretically grounded estimators that leverage structured measurements of the confounders during training, but allow estimating personalized treatment effects purely from unstructured inputs, while avoiding confounding bias. When these structured measurements are only available for a non-representative subset of the data, these estimators may suffer from sampling bias. To address this, we further introduce a regression-based correction that accounts for the non-uniform sampling, assuming the sampling mechanism is known or can be well-estimated. Our experiments on two benchmark datasets show that the plug-in method, directly trainable on large unstructured datasets, achieves strong empirical performance across all settings, despite its simplicity.
SynSUM -- Synthetic Benchmark with Structured and Unstructured Medical Records
Sep 13, 2024We present the SynSUM benchmark, a synthetic dataset linking unstructured clinical notes to structured background variables. The dataset consists of 10,000 artificial patient records containing tabular variables (like symptoms, diagnoses and underlying conditions) and related notes describing the fictional patient encounter in the domain of respiratory diseases. The tabular portion of the data is generated through a Bayesian network, where both the causal structure between the variables and the conditional probabilities are proposed by an expert based on domain knowledge. We then prompt a large language model (GPT-4o) to generate a clinical note related to this patient encounter, describing the patient symptoms and additional context. The SynSUM dataset is primarily designed to facilitate research on clinical information extraction in the presence of tabular background variables, which can be linked through domain knowledge to concepts of interest to be extracted from the text - the symptoms, in the case of SynSUM. Secondary uses include research on the automation of clinical reasoning over both tabular data and text, causal effect estimation in the presence of tabular and/or textual confounders, and multi-modal synthetic data generation. The dataset can be downloaded from https://github.com/prabaey/SynSUM.
Next-Year Bankruptcy Prediction from Textual Data: Benchmark and Baselines
Aug 24, 2022



Models for bankruptcy prediction are useful in several real-world scenarios, and multiple research contributions have been devoted to the task, based on structured (numerical) as well as unstructured (textual) data. However, the lack of a common benchmark dataset and evaluation strategy impedes the objective comparison between models. This paper introduces such a benchmark for the unstructured data scenario, based on novel and established datasets, in order to stimulate further research into the task. We describe and evaluate several classical and neural baseline models, and discuss benefits and flaws of different strategies. In particular, we find that a lightweight bag-of-words model based on static in-domain word representations obtains surprisingly good results, especially when taking textual data from several years into account. These results are critically assessed, and discussed in light of particular aspects of the data and the task. All code to replicate the data and experimental results will be released.