 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Long-term Iterative Mining Scheme for Video Salient Object Detection
Jun 20, 2022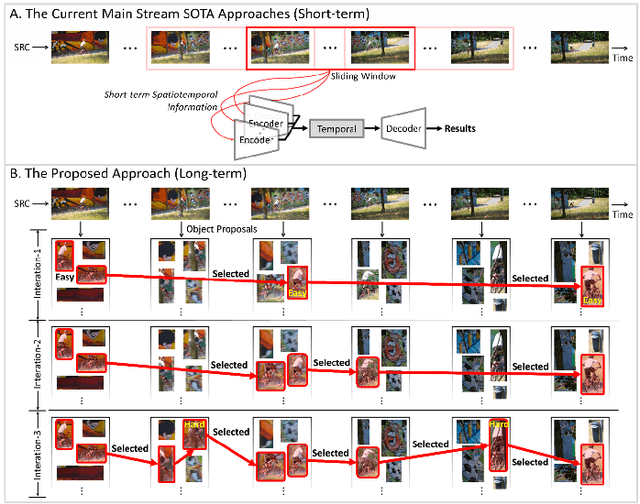
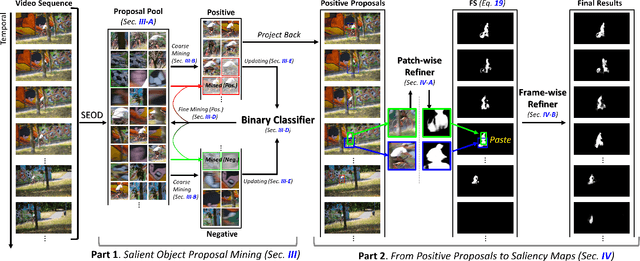


The existing state-of-the-art (SOTA) video salient object detection (VSOD) models have widely followed short-term methodology, which dynamically determines the balance between spatial and temporal saliency fusion by solely considering the current consecutive limited frames. However, the short-term methodology has one critical limitation, which conflicts with the real mechanism of our visual system -- a typical long-term methodology. As a result, failure cases keep showing up in the results of the current SOTA models, and the short-term methodology becomes the major technical bottleneck. To solve this problem, this paper proposes a novel VSOD approach, which performs VSOD in a complete long-term way. Our approach converts the sequential VSOD, a sequential task, to a data mining problem, i.e., decomposing the input video sequence to object proposals in advance and then mining salient object proposals as much as possible in an easy-to-hard way. Since all object proposals are simultaneously available, the proposed approach is a complete long-term approach, which can alleviate some difficulties rooted in conventional short-term approaches. In addition, we devised an online updating scheme that can grasp the most representative and trustworthy pattern profile of the salient objects, outputting framewise saliency maps with rich details and smoothing both spatially and temporally. The proposed approach outperforms almost all SOTA models on five widely used benchmark datasets.