 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task and Multi-Modal Learning for RGB Dynamic Gesture Recognition
Oct 29, 2021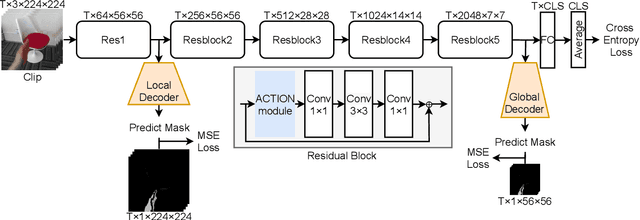
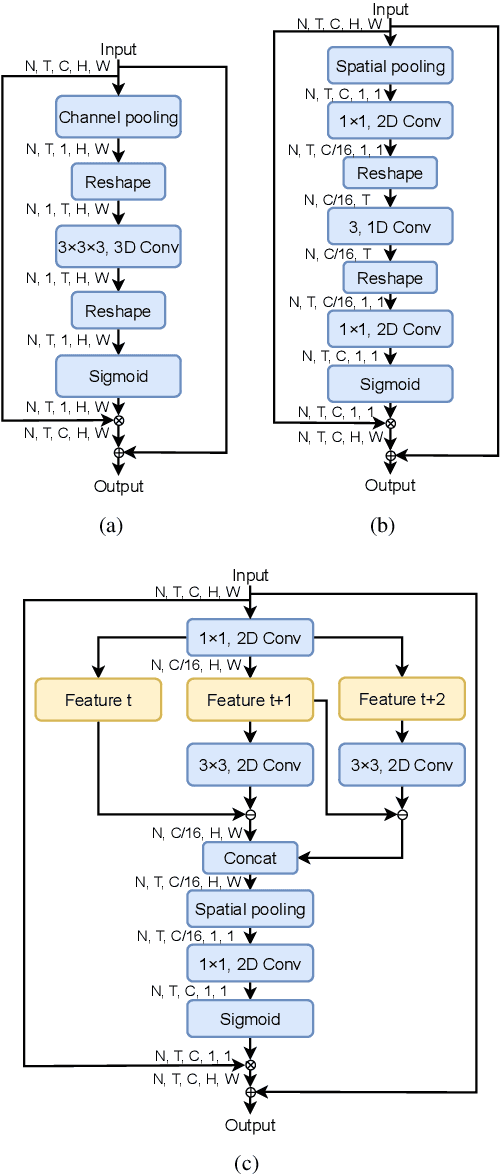


Gesture recognition is getting more and more popular due to various application possibilities in human-machine interaction. Existing multi-modal gesture recognition systems take multi-modal data as input to improve accuracy, but such methods require more modality sensors, which will greatly limit their application scenarios. Therefore we propose an end-to-end multi-task learning framework in training 2D convolutional neural networks. The framework can use the depth modality to improve accuracy during training and save costs by using only RGB modality during inference. Our framework is trained to learn a representation for multi-task learning: gesture segmentation and gesture recognition. Depth modality contains the prior information for the location of the gesture. Therefore it can be used as the supervision for gesture segmentation. A plug-and-play module named Multi-Scale-Decoder is designed to realize gesture segmentation, which contains two sub-decoder. It is used in the lower stage and higher stage respectively, and can help the network pay attention to key target areas, ignore irrelevant information, and extract more discriminant features. Additionally, the MSD module and depth modality are only used in the training stage to improve gesture recognition performance. Only RGB modality and network without MSD are required during inference. Experimental results on three public gesture recognition datasets show that our proposed method provides superior performance compared with existing gesture recognition frameworks. Moreover, using the proposed plug-and-play MSD in other 2D CNN-based frameworks also get an excellent accuracy improvement.
SGTBN: Generating Dense Depth Maps from Single-Line LiDAR
Jun 24, 2021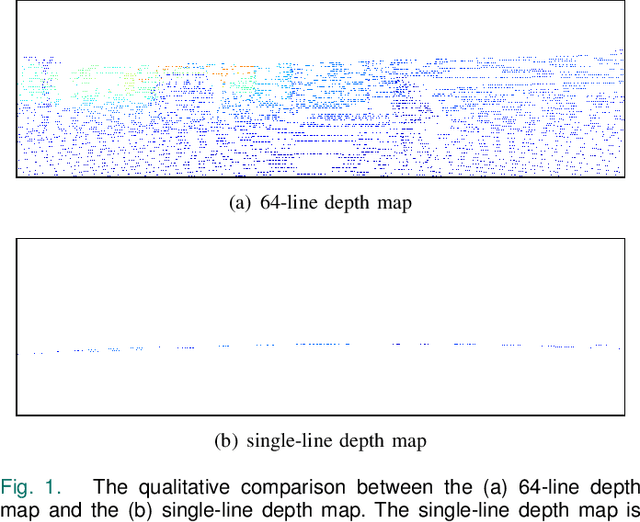
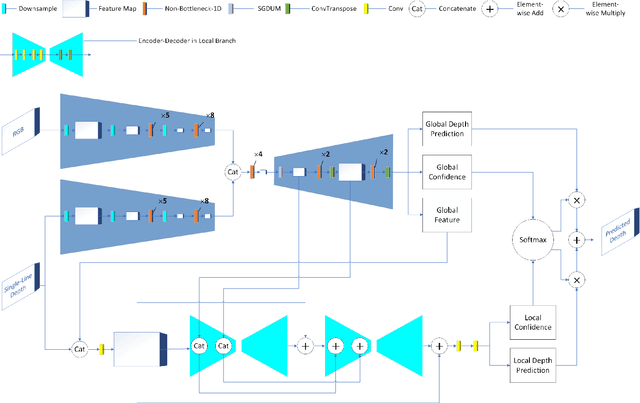
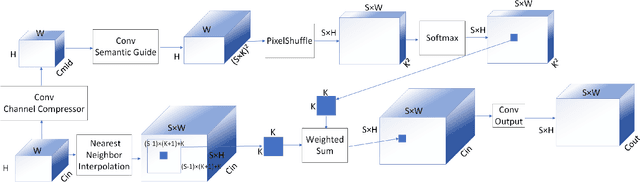
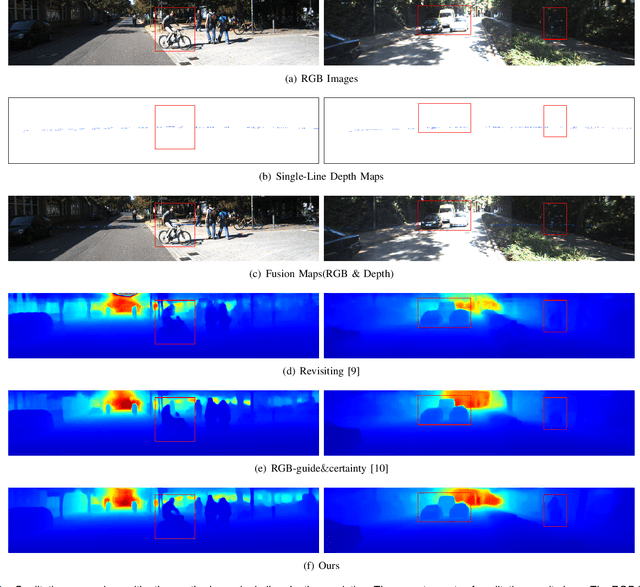
Depth completion aims to generate a dense depth map from the sparse depth map and aligned RGB image. However, current depth completion methods use extremely expensive 64-line LiDAR(about $100,000) to obtain sparse depth maps, which will limit their application scenarios. Compared with the 64-line LiDAR, the single-line LiDAR is much less expensive and much more robust. Therefore, we propose a method to tackle the problem of single-line depth completion, in which we aim to generate a dense depth map from the single-line LiDAR info and the aligned RGB image. A single-line depth completion dataset is proposed based on the existing 64-line depth completion dataset(KITTI). A network called Semantic Guided Two-Branch Network(SGTBN) which contains global and local branches to extract and fuse global and local info is proposed for this task. A Semantic guided depth upsampling module is used in our network to make full use of the semantic info in RGB images. Except for the usual MSE loss, we add the virtual normal loss to increase the constraint of high-order 3D geometry in our network. Our network outperforms the state-of-the-art in the single-line depth completion task. Besides, compared with the monocular depth estimation, our method also has significant advantages in precision and model size.