 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Glycemic Impact of Cooking Recipes via Online Crowdsourcing and Machine Learning
Sep 17, 2019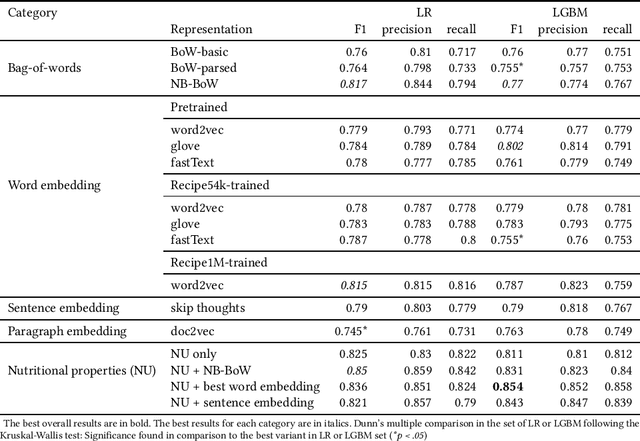
Consumption of diets with low glycemic impact is highly recommended for diabetics and pre-diabetics as it helps maintain their blood glucose levels. However, laboratory analysis of dietary glycemic potency is time-consuming and expensive. In this paper, we explore a data-driven approach utilizing online crowdsourcing and machine learning to estimate the glycemic impact of cooking recipes. We show that a commonly used healthiness metric may not always be effective in determining recipes suitable for diabetics, thus emphasizing the importance of the glycemic-impact estimation task. Our best classification model, trained on nutritional and crowdsourced data obtained from Amazon Mechanical Turk (AMT), can accurately identify recipes which are unhealthful for diabetics.
Characterizing and Predicting Repeat Food Consumption Behavior for Just-in-Time Interventions
Sep 17, 2019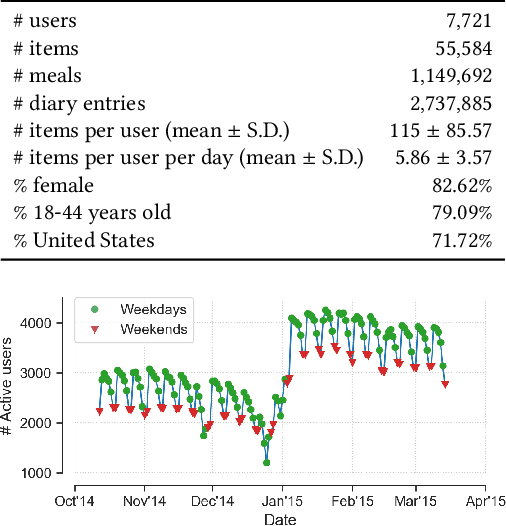
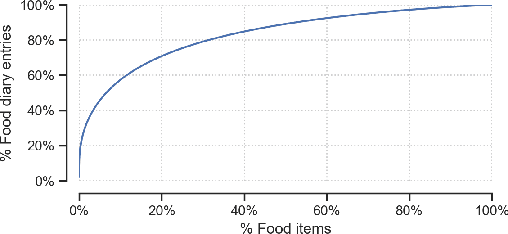

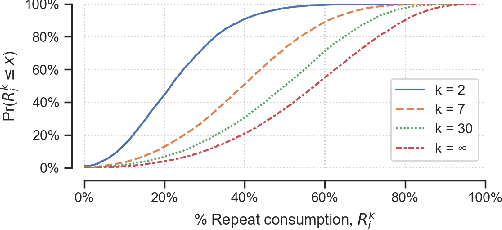
Human beings are creatures of habit. In their daily life, people tend to repeatedly consume similar types of food items over several days and occasionally switch to consuming different types of items when the consumptions become overly monotonous. However, the novel and repeat consumption behaviors have not been studied in food recommendation research. More importantly, the ability to predict daily eating habits of individuals is crucial to improve the effectiveness of food recommender systems in facilitating healthy lifestyle change. In this study, we analyze the patterns of repeat food consumptions using large-scale consumption data from a popular online fitness community called MyFitnessPal (MFP), conduct an offline evaluation of various state-of-the-art algorithms in predicting the next-day food consumption, and analyze their performance across different demographic groups and contexts. The experiment results show that algorithms incorporating the exploration-and-exploitation and temporal dynamics are more effective in the next-day recommendation task than most state-of-the-art algorithms.