 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Generalized Zero Shot Learning for the Classification of Disease in Chest Radiographs
Jul 14, 2021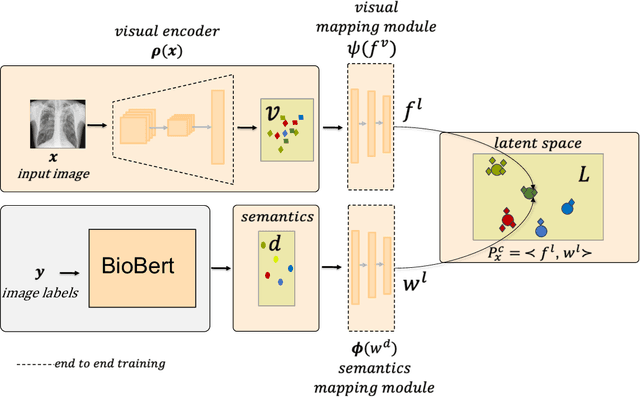
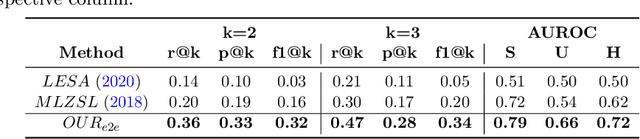
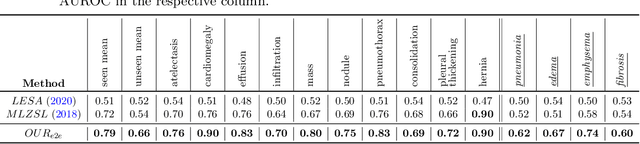
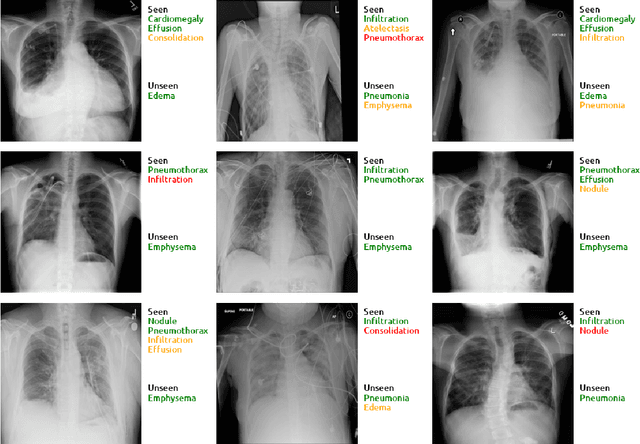
Despite the success of deep neural networks in chest X-ray (CXR) diagnosis, supervised learning only allows the prediction of disease classes that were seen during training. At inference, these networks cannot predict an unseen disease class. Incorporating a new class requires the collection of labeled data, which is not a trivial task, especially for less frequently-occurring diseases. As a result, it becomes inconceivable to build a model that can diagnose all possible disease classes. Here, we propose a multi-label generalized zero shot learning (CXR-ML-GZSL) network that can simultaneously predict multiple seen and unseen diseases in CXR images. Given an input image, CXR-ML-GZSL learns a visual representation guided by the input's corresponding semantics extracted from a rich medical text corpus. Towards this ambitious goal, we propose to map both visual and semantic modalities to a latent feature space using a novel learning objective. The objective ensures that (i) the most relevant labels for the query image are ranked higher than irrelevant labels, (ii) the network learns a visual representation that is aligned with its semantics in the latent feature space, and (iii) the mapped semantics preserve their original inter-class representation. The network is end-to-end trainable and requires no independent pre-training for the offline feature extractor. Experiments on the NIH Chest X-ray dataset show that our network outperforms two strong baselines in terms of recall, precision, f1 score, and area under the receiver operating characteristic curve. Our code is publicly available at: https://github.com/nyuad-cai/CXR-ML-GZSL.git