 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Reduction Convolutional Neural Network Policy for Financial Deep Reinforcement Learning
Aug 16, 2024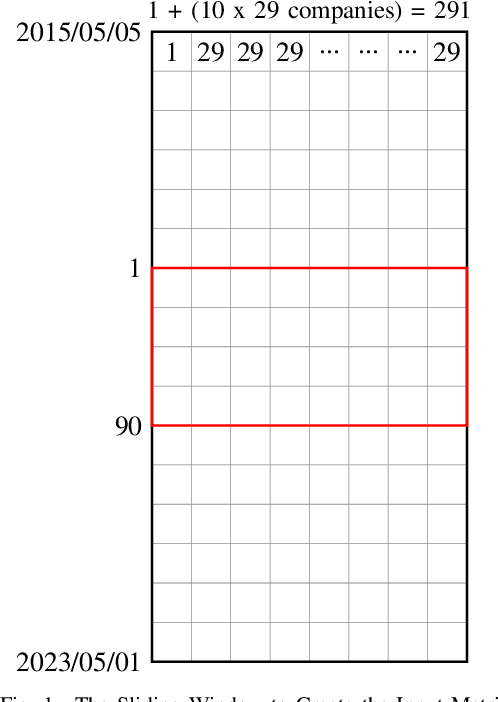
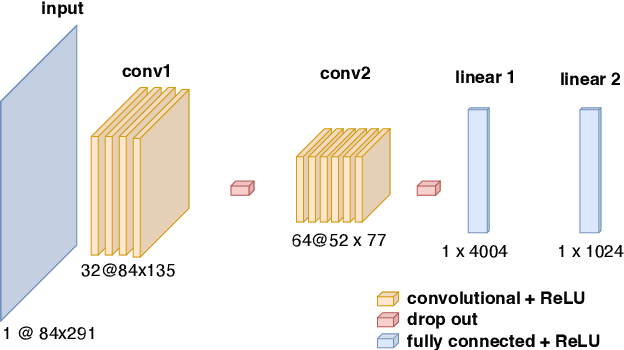
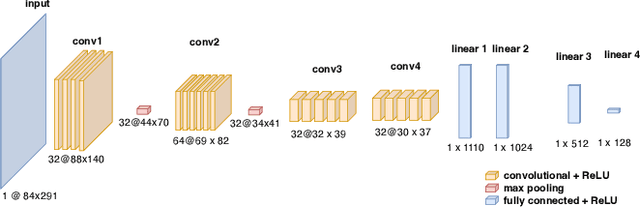
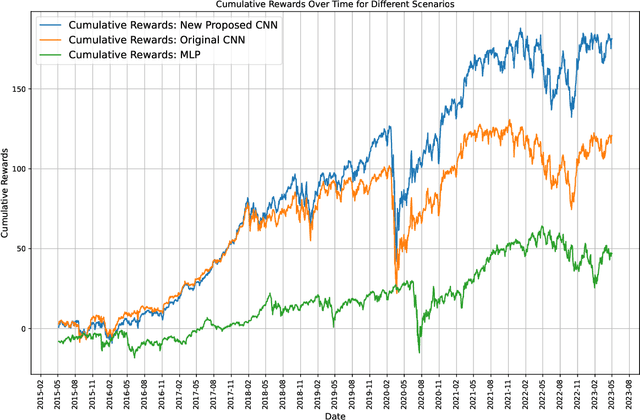
Building on our prior explorations of convolutional neural networks (CNNs) for financial data processing, this paper introduces two significant enhancements to refine our CNN model's predictive performance and robustness for financial tabular data. Firstly, we integrate a normalization layer at the input stage to ensure consistent feature scaling, addressing the issue of disparate feature magnitudes that can skew the learning process. This modification is hypothesized to aid in stabilizing the training dynamics and improving the model's generalization across diverse financial datasets. Secondly, we employ a Gradient Reduction Architecture, where earlier layers are wider and subsequent layers are progressively narrower. This enhancement is designed to enable the model to capture more complex and subtle patterns within the data, a crucial factor in accurately predicting financial outcomes. These advancements directly respond to the limitations identified in previous studies, where simpler models struggled with the complexity and variability inherent in financial applications. Initial tests confirm that these changes improve accuracy and model stability, suggesting that deeper and more nuanced network architectures can significantly benefit financial predictive tasks. This paper details the implementation of these enhancements and evaluates their impact on the model's performance in a controlled experimental setting.
CNN-DRL for Scalable Actions in Finance
Jan 10, 2024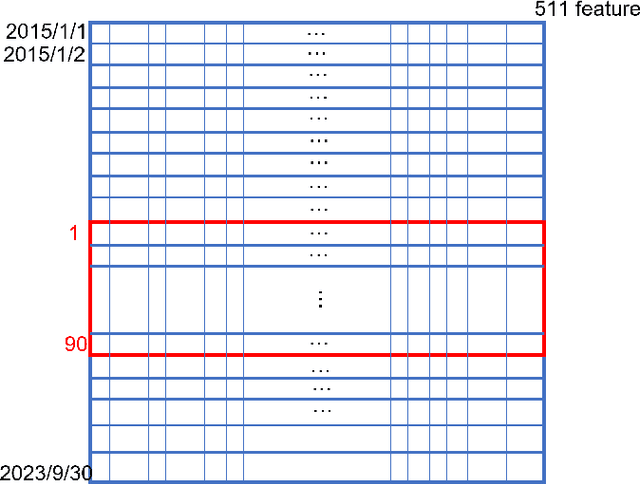
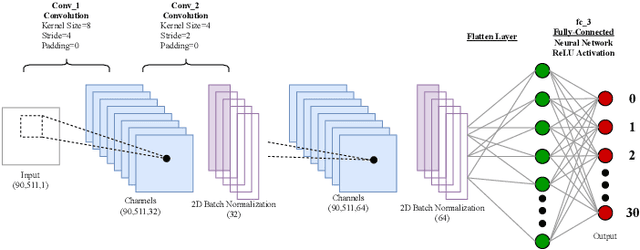
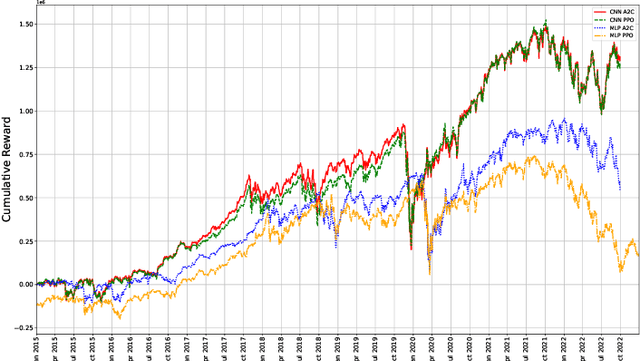
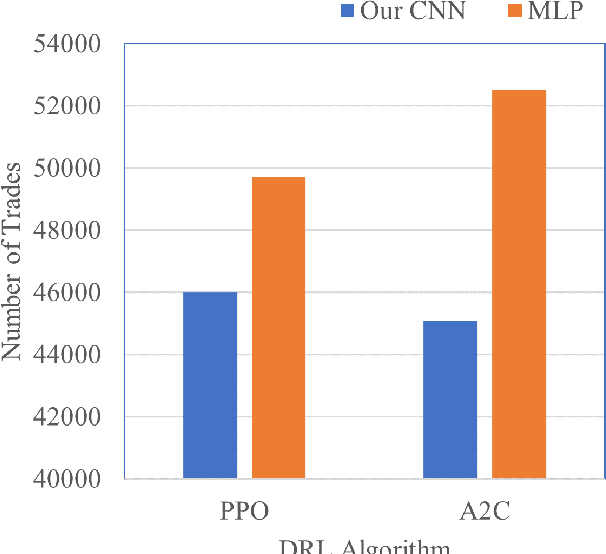
The published MLP-based DRL in finance has difficulties in learning the dynamics of the environment when the action scale increases. If the buying and selling increase to one thousand shares, the MLP agent will not be able to effectively adapt to the environment. To address this, we designed a CNN agent that concatenates the data from the last ninety days of the daily feature vector to create the CNN input matrix. Our extensive experiments demonstrate that the MLP-based agent experiences a loss corresponding to the initial environment setup, while our designed CNN remains stable, effectively learns the environment, and leads to an increase in rewards.