Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN-DRL for Scalable Actions in Finance
Paper and Code
Jan 10, 2024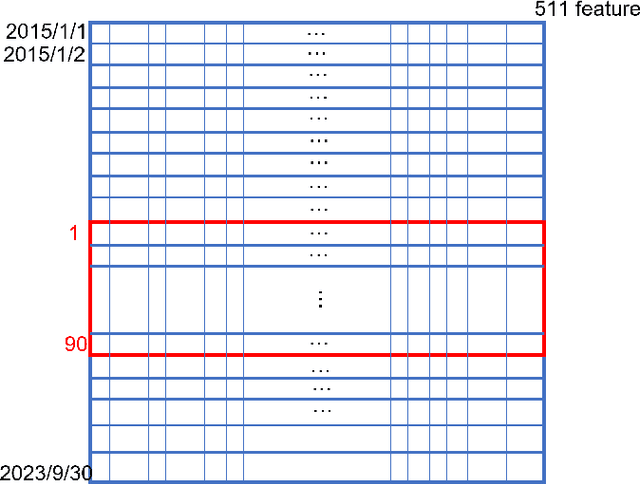
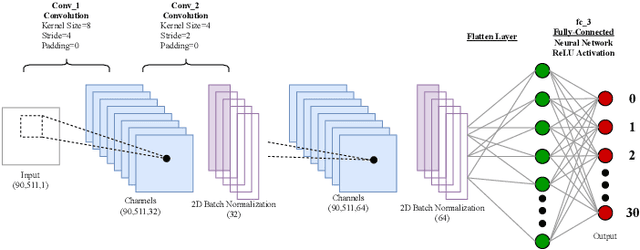
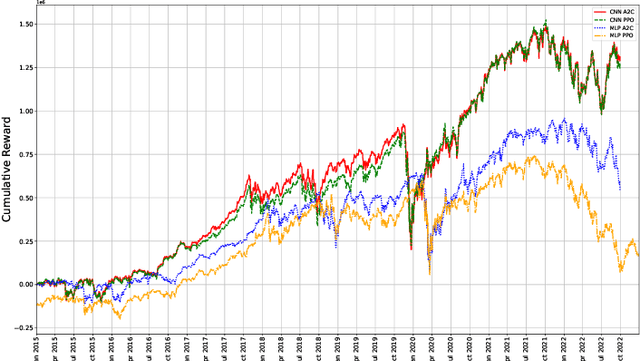
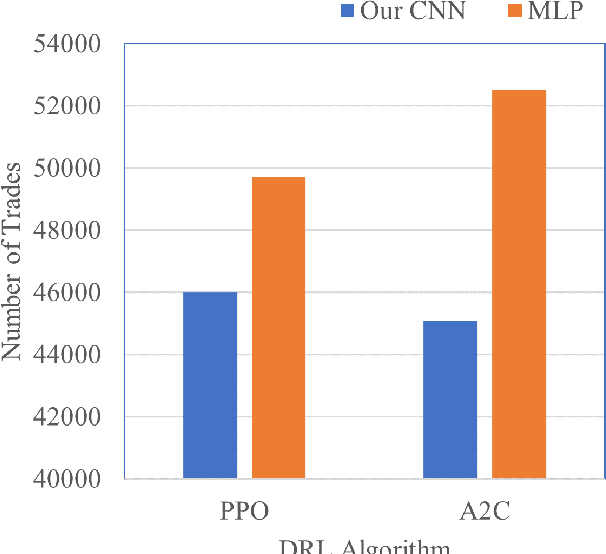
The published MLP-based DRL in finance has difficulties in learning the dynamics of the environment when the action scale increases. If the buying and selling increase to one thousand shares, the MLP agent will not be able to effectively adapt to the environment. To address this, we designed a CNN agent that concatenates the data from the last ninety days of the daily feature vector to create the CNN input matrix. Our extensive experiments demonstrate that the MLP-based agent experiences a loss corresponding to the initial environment setup, while our designed CNN remains stable, effectively learns the environment, and leads to an increase in rewards.
* 10th Annual Conf. on Computational Science & Computational
Intelligence
View paper on