 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding Box Priors for Cell Detection with Point Annotations
Nov 11, 2022

The size of an individual cell type, such as a red blood cell, does not vary much among humans. We use this knowledge as a prior for classifying and detecting cells in images with only a few ground truth bounding box annotations, while most of the cells are annotated with points. This setting leads to weakly semi-supervised learning. We propose replacing points with either stochastic (ST) boxes or bounding box predictions during the training process. The proposed "mean-IOU" ST box maximizes the overlap with all the boxes belonging to the sample space with a class-specific approximated prior probability distribution of bounding boxes. Our method trains with both box- and point-labelled images in conjunction, unlike the existing methods, which train first with box- and then point-labelled images. In the most challenging setting, when only 5% images are box-labelled, quantitative experiments on a urine dataset show that our one-stage method outperforms two-stage methods by 5.56 mAP. Furthermore, we suggest an approach that partially answers "how many box-labelled annotations are necessary?" before training a machine learning model.
Urine Microscopic Image Dataset
Nov 19, 2021Urinalysis is a standard diagnostic test to detect urinary system related problems. The automation of urinalysis will reduce the overall diagnostic time. Recent studies used urine microscopic datasets for designing deep learning based algorithms to classify and detect urine cells. But these datasets are not publicly available for further research. To alleviate the need for urine datsets, we prepare our urine sediment microscopic image (UMID) dataset comprising of around 3700 cell annotations and 3 categories of cells namely RBC, pus and epithelial cells. We discuss the several challenges involved in preparing the dataset and the annotations. We make the dataset publicly available.
Accelerating the Registration of Image Sequences by Spatio-temporal Multilevel Strategies
Jan 18, 2020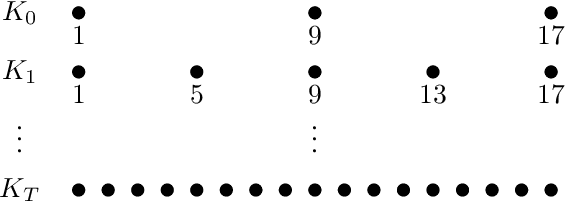
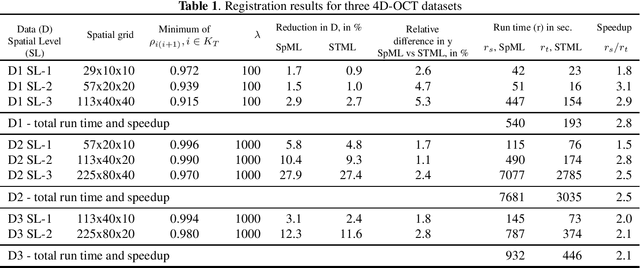
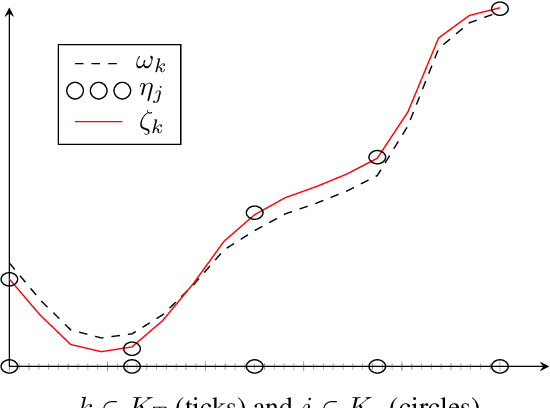

Multilevel strategies are an integral part of many image registration algorithms. These strategies are very well-known for avoiding undesirable local minima, providing an outstanding initial guess, and reducing overall computation time. State-of-the-art multilevel strategies build a hierarchy of discretization in the spatial dimensions. In this paper, we present a spatio-temporal strategy, where we introduce a hierarchical discretization in the temporal dimension at each spatial level. This strategy is suitable for a motion estimation problem where the motion is assumed smooth over time. Our strategy exploits the temporal smoothness among image frames by following a predictor-corrector approach. The strategy predicts the motion by a novel interpolation method and later corrects it by registration. The prediction step provides a good initial guess for the correction step, hence reduces the overall computational time for registration. The acceleration is achieved by a factor of 2.5 on average, over the state-of-the-art multilevel methods on three examined optical coherence tomography datasets.
Variational Registration of Multiple Images with the SVD based SqN Distance Measure
Jul 23, 2019
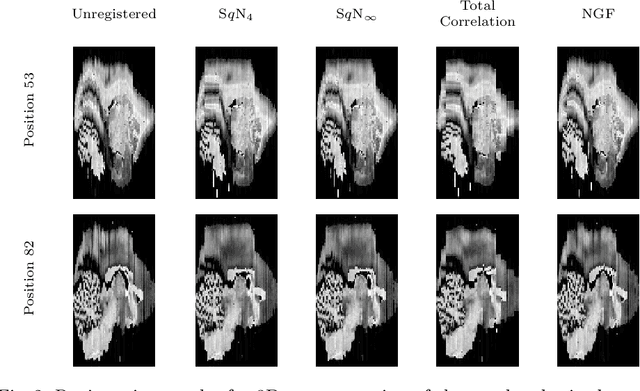
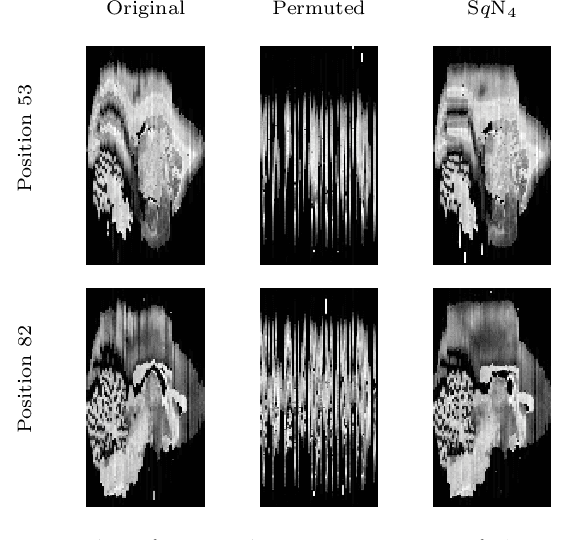
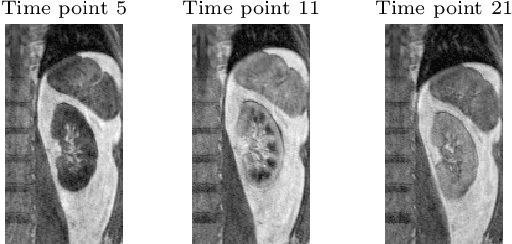
Image registration, especially the quantification of image similarity, is an important task in image processing. Various approaches for the comparison of two images are discussed in the literature. However, although most of these approaches perform very well in a two image scenario, an extension to a multiple images scenario deserves attention. In this article, we discuss and compare registration methods for multiple images. Our key assumption is, that information about the singular values of a feature matrix of images can be used for alignment. We introduce, discuss and relate three recent approaches from the literature: the Schatten q-norm based SqN distance measure, a rank based approach, and a feature volume based approach. We also present results for typical applications such as dynamic image sequences or stacks of histological sections. Our results indicate that the SqN approach is in fact a suitable distance measure for image registration. Moreover, our examples also indicate that the results obtained by SqN are superior to those obtained by its competitors.