 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Perception-Based L2 Speech Intelligibility Indicator: Leveraging a Rater's Shadowing and Sequence-to-sequence Voice Conversion
May 30, 2025


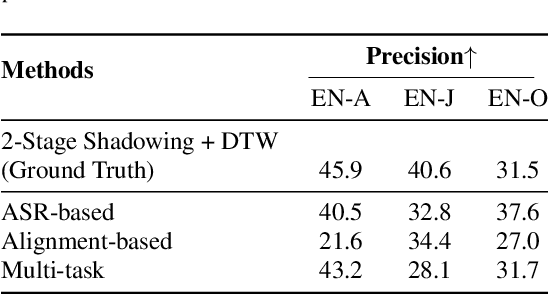
Evaluating L2 speech intelligibility is crucial for effective computer-assisted language learning (CALL). Conventional ASR-based methods often focus on native-likeness, which may fail to capture the actual intelligibility perceived by human listeners. In contrast, our work introduces a novel, perception based L2 speech intelligibility indicator that leverages a native rater's shadowing data within a sequence-to-sequence (seq2seq) voice conversion framework. By integrating an alignment mechanism and acoustic feature reconstruction, our approach simulates the auditory perception of native listeners, identifying segments in L2 speech that are likely to cause comprehension difficulties. Both objective and subjective evaluations indicate that our method aligns more closely with native judgments than traditional ASR-based metrics, offering a promising new direction for CALL systems in a global, multilingual contexts.
A Pilot Study of Applying Sequence-to-Sequence Voice Conversion to Evaluate the Intelligibility of L2 Speech Using a Native Speaker's Shadowings
Oct 03, 2024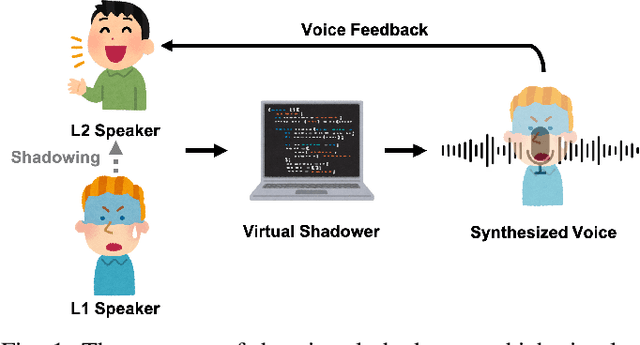
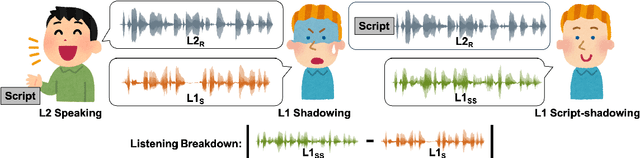

Utterances by L2 speakers can be unintelligible due to mispronunciation and improper prosody. In computer-aided language learning systems, textual feedback is often provided using a speech recognition engine. However, an ideal form of feedback for L2 speakers should be so fine-grained that it enables them to detect and diagnose unintelligible parts of L2 speakers' utterances. Inspired by language teachers who correct students' pronunciation through a voice-to-voice process, this pilot study utilizes a unique semi-parallel dataset composed of non-native speakers' (L2) reading aloud, shadowing of native speakers (L1) and their script-shadowing utterances. We explore the technical possibility of replicating the process of an L1 speaker's shadowing L2 speech using Voice Conversion techniques, to create a virtual shadower system. Experimental results demonstrate the feasibility of the VC system in simulating L1's shadowing behavior. The output of the virtual shadower system shows a reasonable similarity to the real L1 shadowing utterances in both linguistic and acoustic aspects.
Simulating Native Speaker Shadowing for Nonnative Speech Assessment with Latent Speech Representations
Sep 19, 2024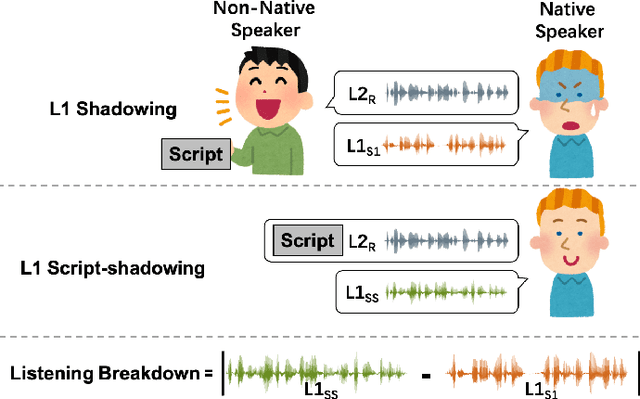
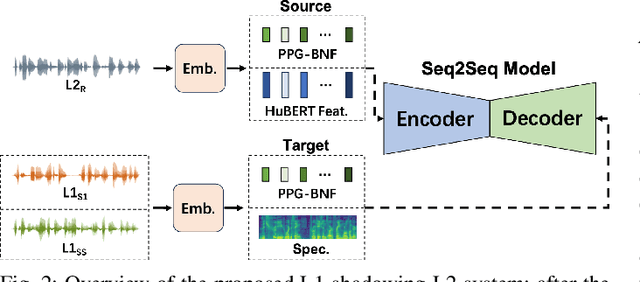
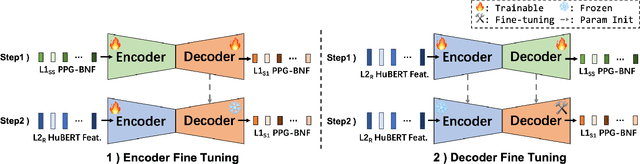
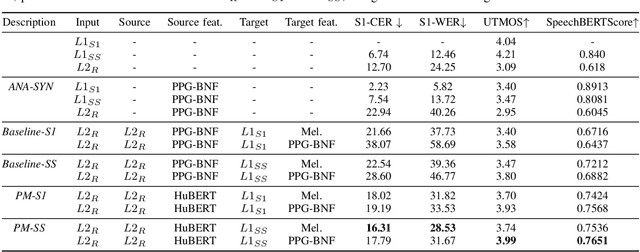
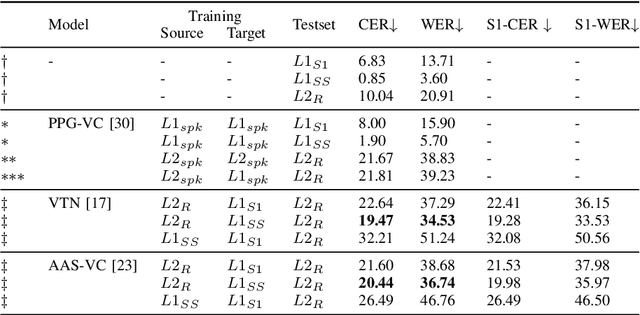
Evaluating speech intelligibility is a critical task in computer-aided language learning systems. Traditional methods often rely on word error rates (WER) provided by automatic speech recognition (ASR) as intelligibility scores. However, this approach has significant limitations due to notable differences between human speech recognition (HSR) and ASR. A promising alternative is to involve a native (L1) speaker in shadowing what nonnative (L2) speakers say. Breakdowns or mispronunciations in the L1 speaker's shadowing utterance can serve as indicators for assessing L2 speech intelligibility. In this study, we propose a speech generation system that simulates the L1 shadowing process using voice conversion (VC) techniques and latent speech representations. Our experimental results demonstrate that this method effectively replicates the L1 shadowing process, offering an innovative tool to evaluate L2 speech intelligibility. Notably, systems that utilize self-supervised speech representations (S3R) show a higher degree of similarity to real L1 shadowing utterances in both linguistic accuracy and naturalness.