 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Deep Q-Learning
Oct 15, 2015



We propose a distributed deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is based on the deep Q-network, a convolutional neural network trained with a variant of Q-learning. Its input is raw pixels and its output is a value function estimating future rewards from taking an action given a system state. To distribute the deep Q-network training, we adapt the DistBelief software framework to the context of efficiently training reinforcement learning agents. As a result, the method is completely asynchronous and scales well with the number of machines. We demonstrate that the deep Q-network agent, receiving only the pixels and the game score as inputs, was able to achieve reasonable success on a simple game with minimal parameter tuning.
Value function approximation via low-rank models
Aug 31, 2015
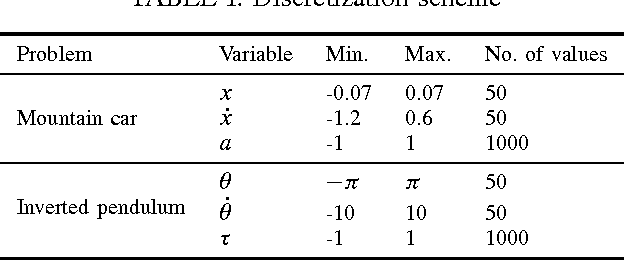

We propose a novel value function approximation technique for Markov decision processes. We consider the problem of compactly representing the state-action value function using a low-rank and sparse matrix model. The problem is to decompose a matrix that encodes the true value function into low-rank and sparse components, and we achieve this using Robust Principal Component Analysis (PCA). Under minimal assumptions, this Robust PCA problem can be solved exactly via the Principal Component Pursuit convex optimization problem. We experiment the procedure on several examples and demonstrate that our method yields approximations essentially identical to the true function.