 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEDLIoT -- Next generation accelerated AIoT systems and applications
May 09, 2023The VEDLIoT project aims to develop energy-efficient Deep Learning methodologies for distributed Artificial Intelligence of Things (AIoT) applications. During our project, we propose a holistic approach that focuses on optimizing algorithms while addressing safety and security challenges inherent to AIoT systems. The foundation of this approach lies in a modular and scalable cognitive IoT hardware platform, which leverages microserver technology to enable users to configure the hardware to meet the requirements of a diverse array of applications. Heterogeneous computing is used to boost performance and energy efficiency. In addition, the full spectrum of hardware accelerators is integrated, providing specialized ASICs as well as FPGAs for reconfigurable computing. The project's contributions span across trusted computing, remote attestation, and secure execution environments, with the ultimate goal of facilitating the design and deployment of robust and efficient AIoT systems. The overall architecture is validated on use-cases ranging from Smart Home to Automotive and Industrial IoT appliances. Ten additional use cases are integrated via an open call, broadening the range of application areas.
* This publication incorporates results from the VEDLIoT project, which received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 957197. CF'23: 20th ACM International Conference on Computing Frontiers, May 2023, Bologna, Italy
Automotive Perception Software Development: An Empirical Investigation into Data, Annotation, and Ecosystem Challenges
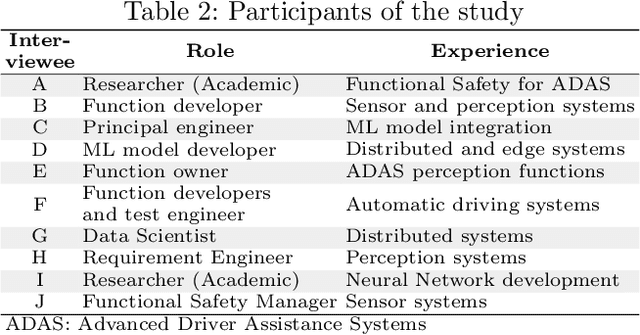
Mar 10, 2023Software that contains machine learning algorithms is an integral part of automotive perception, for example, in driving automation systems. The development of such software, specifically the training and validation of the machine learning components, require large annotated datasets. An industry of data and annotation services has emerged to serve the development of such data-intensive automotive software components. Wide-spread difficulties to specify data and annotation needs challenge collaborations between OEMs (Original Equipment Manufacturers) and their suppliers of software components, data, and annotations. This paper investigates the reasons for these difficulties for practitioners in the Swedish automotive industry to arrive at clear specifications for data and annotations. The results from an interview study show that a lack of effective metrics for data quality aspects, ambiguities in the way of working, unclear definitions of annotation quality, and deficits in the business ecosystems are causes for the difficulty in deriving the specifications. We provide a list of recommendations that can mitigate challenges when deriving specifications and we propose future research opportunities to overcome these challenges. Our work contributes towards the on-going research on accountability of machine learning as applied to complex software systems, especially for high-stake applications such as automated driving.
An investigation of challenges encountered when specifying training data and runtime monitors for safety critical ML applications
Jan 31, 2023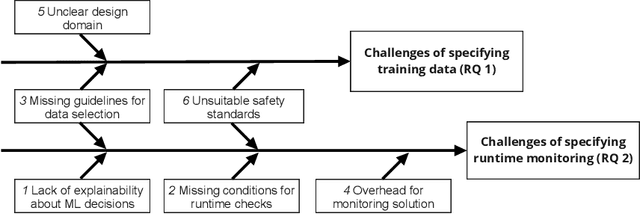

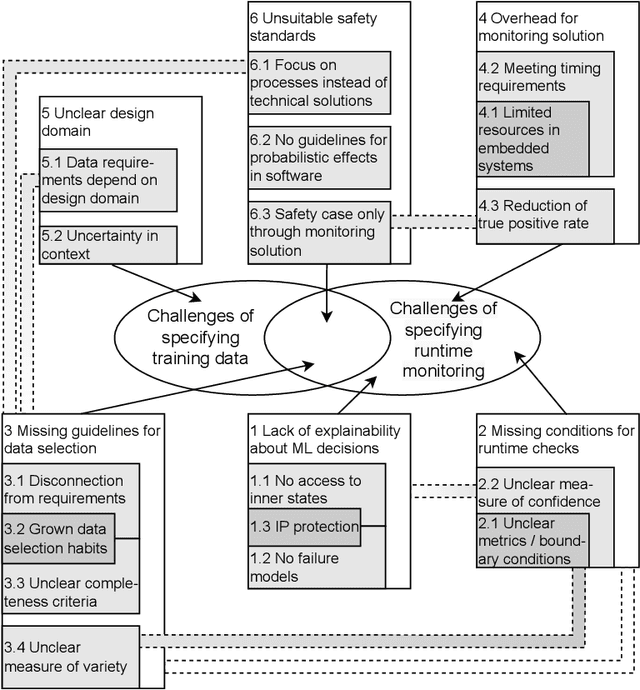
Context and motivation: The development and operation of critical software that contains machine learning (ML) models requires diligence and established processes. Especially the training data used during the development of ML models have major influences on the later behaviour of the system. Runtime monitors are used to provide guarantees for that behaviour. Question / problem: We see major uncertainty in how to specify training data and runtime monitoring for critical ML models and by this specifying the final functionality of the system. In this interview-based study we investigate the underlying challenges for these difficulties. Principal ideas/results: Based on ten interviews with practitioners who develop ML models for critical applications in the automotive and telecommunication sector, we identified 17 underlying challenges in 6 challenge groups that relate to the challenge of specifying training data and runtime monitoring. Contribution: The article provides a list of the identified underlying challenges related to the difficulties practitioners experience when specifying training data and runtime monitoring for ML models. Furthermore, interconnection between the challenges were found and based on these connections recommendation proposed to overcome the root causes for the challenges.
A Compositional Approach to Creating Architecture Frameworks with an Application to Distributed AI Systems
Dec 27, 2022Artificial intelligence (AI) in its various forms finds more and more its way into complex distributed systems. For instance, it is used locally, as part of a sensor system, on the edge for low-latency high-performance inference, or in the cloud, e.g. for data mining. Modern complex systems, such as connected vehicles, are often part of an Internet of Things (IoT). To manage complexity, architectures are described with architecture frameworks, which are composed of a number of architectural views connected through correspondence rules. Despite some attempts, the definition of a mathematical foundation for architecture frameworks that are suitable for the development of distributed AI systems still requires investigation and study. In this paper, we propose to extend the state of the art on architecture framework by providing a mathematical model for system architectures, which is scalable and supports co-evolution of different aspects for example of an AI system. Based on Design Science Research, this study starts by identifying the challenges with architectural frameworks. Then, we derive from the identified challenges four rules and we formulate them by exploiting concepts from category theory. We show how compositional thinking can provide rules for the creation and management of architectural frameworks for complex systems, for example distributed systems with AI. The aim of the paper is not to provide viewpoints or architecture models specific to AI systems, but instead to provide guidelines based on a mathematical formulation on how a consistent framework can be built up with existing, or newly created, viewpoints. To put in practice and test the approach, the identified and formulated rules are applied to derive an architectural framework for the EU Horizon 2020 project ``Very efficient deep learning in the IoT" (VEDLIoT) in the form of a case study.
Setting AI in context: A case study on defining the context and operational design domain for automated driving
Jan 27, 2022
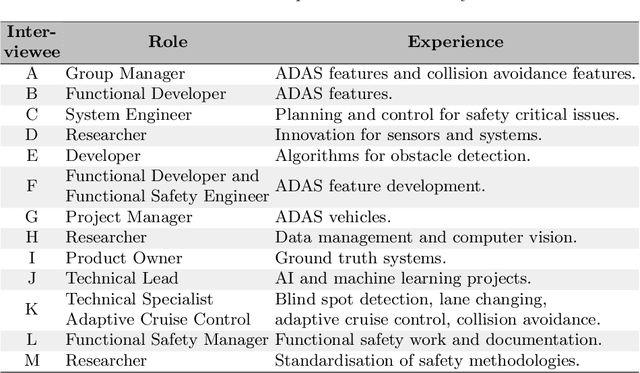


[Context and motivation] For automated driving systems, the operational context needs to be known in order to state guarantees on performance and safety. The operational design domain (ODD) is an abstraction of the operational context, and its definition is an integral part of the system development process. [Question / problem] There are still major uncertainties in how to clearly define and document the operational context in a diverse and distributed development environment such as the automotive industry. This case study investigates the challenges with context definitions for the development of perception functions that use machine learning for automated driving. [Principal ideas/results] Based on qualitative analysis of data from semi-structured interviews, the case study shows that there is a lack of standardisation for context definitions across the industry, ambiguities in the processes that lead to deriving the ODD, missing documentation of assumptions about the operational context, and a lack of involvement of function developers in the context definition. [Contribution] The results outline challenges experienced by an automotive supplier company when defining the operational context for systems using machine learning. Furthermore, the study collected ideas for potential solutions from the perspective of practitioners.
Requirement Engineering Challenges for AI-intense Systems Development
Mar 22, 2021



Availability of powerful computation and communication technology as well as advances in artificial intelligence enable a new generation of complex, AI-intense systems and applications. Such systems and applications promise exciting improvements on a societal level, yet they also bring with them new challenges for their development. In this paper we argue that significant challenges relate to defining and ensuring behaviour and quality attributes of such systems and applications. We specifically derive four challenge areas from relevant use cases of complex, AI-intense systems and applications related to industry, transportation, and home automation: understanding, determining, and specifying (i) contextual definitions and requirements, (ii) data attributes and requirements, (iii) performance definition and monitoring, and (iv) the impact of human factors on system acceptance and success. Solving these challenges will imply process support that integrates new requirements engineering methods into development approaches for complex, AI-intense systems and applications. We present these challenges in detail and propose a research roadmap.