 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality on Longitudinal Data: Stable Specification Search in Constrained Structural Equation Modeling
Apr 04, 2017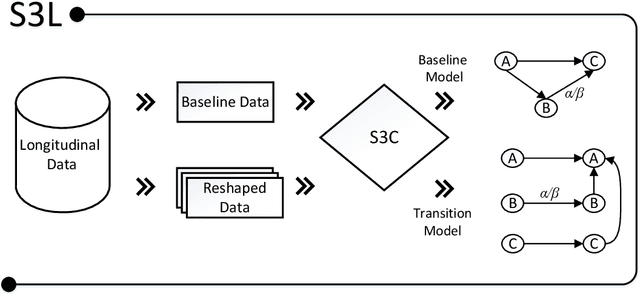
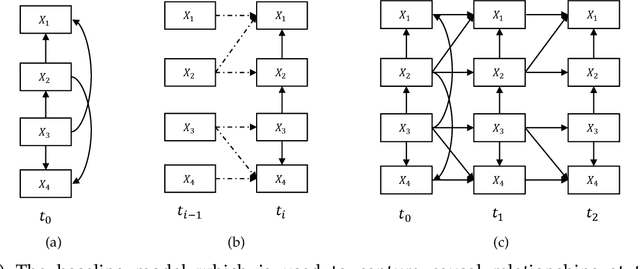
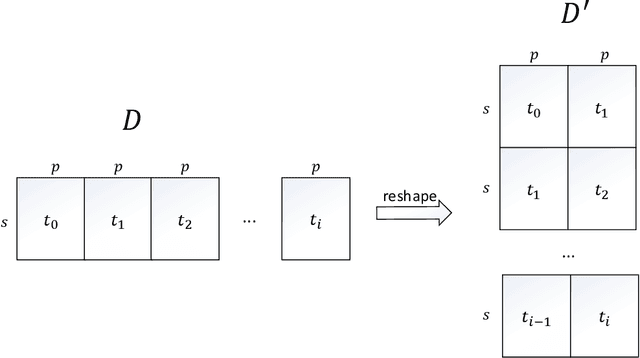
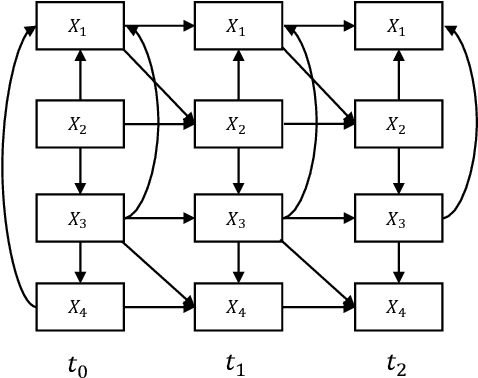
A typical problem in causal modeling is the instability of model structure learning, i.e., small changes in finite data can result in completely different optimal models. The present work introduces a novel causal modeling algorithm for longitudinal data, that is robust for finite samples based on recent advances in stability selection using subsampling and selection algorithms. Our approach uses exploratory search but allows incorporation of prior knowledge, e.g., the absence of a particular causal relationship between two specific variables. We represent causal relationships using structural equation models. Models are scored along two objectives: the model fit and the model complexity. Since both objectives are often conflicting we apply a multi-objective evolutionary algorithm to search for Pareto optimal models. To handle the instability of small finite data samples, we repeatedly subsample the data and select those substructures (from the optimal models) that are both stable and parsimonious. These substructures can be visualized through a causal graph. Our more exploratory approach achieves at least comparable performance as, but often a significant improvement over state-of-the-art alternative approaches on a simulated data set with a known ground truth. We also present the results of our method on three real-world longitudinal data sets on chronic fatigue syndrome, Alzheimer disease, and chronic kidney disease. The findings obtained with our approach are generally in line with results from more hypothesis-driven analyses in earlier studies and suggest some novel relationships that deserve further research.
Causality on Cross-Sectional Data: Stable Specification Search in Constrained Structural Equation Modeling
Jul 14, 2016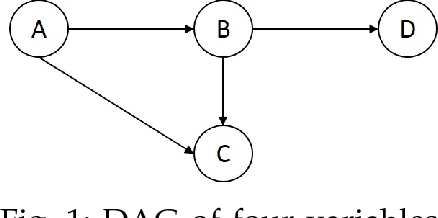
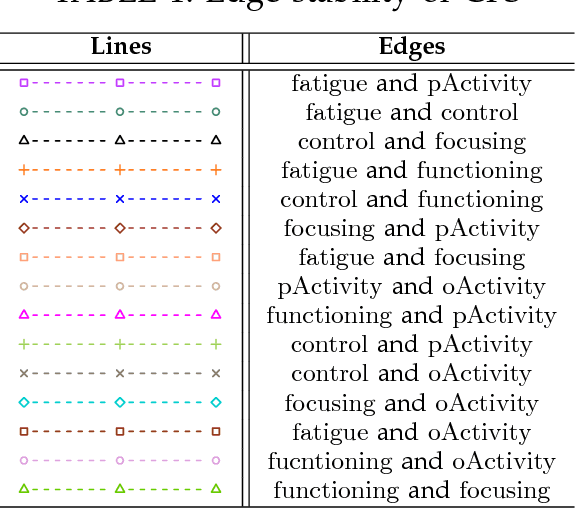
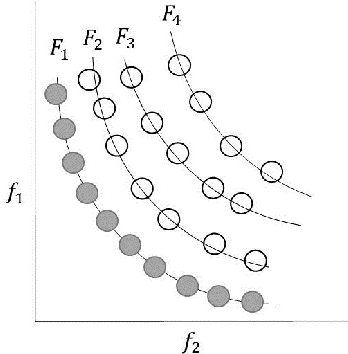
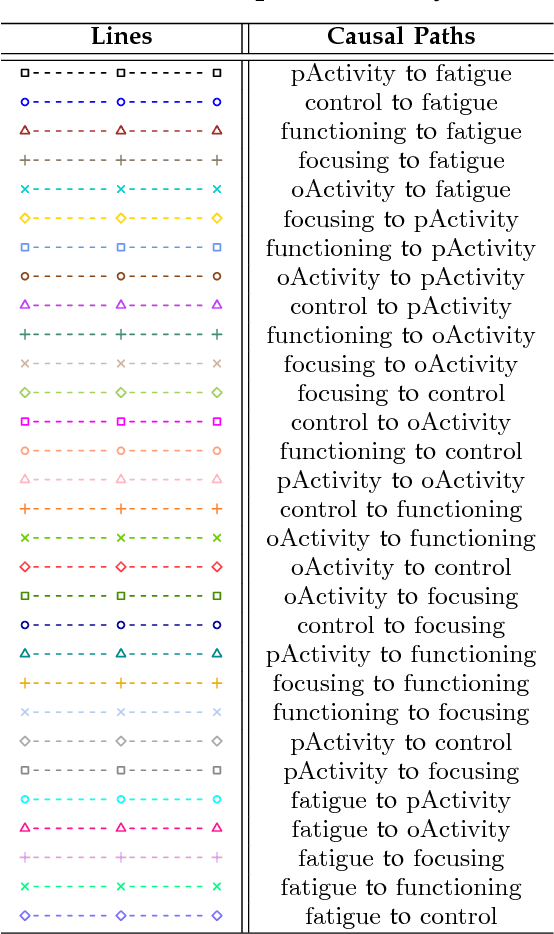
Causal modeling has long been an attractive topic for many researchers and in recent decades there has seen a surge in theoretical development and discovery algorithms. Generally discovery algorithms can be divided into two approaches: constraint-based and score-based. The constraint-based approach is able to detect common causes of the observed variables but the use of independence tests makes it less reliable. The score-based approach produces a result that is easier to interpret as it also measures the reliability of the inferred causal relationships, but it is unable to detect common confounders of the observed variables. A drawback of both score-based and constrained-based approaches is the inherent instability in structure estimation. With finite samples small changes in the data can lead to completely different optimal structures. The present work introduces a new hypothesis-free score-based causal discovery algorithm, called stable specification search, that is robust for finite samples based on recent advances in stability selection using subsampling and selection algorithms. Structure search is performed over Structural Equation Models. Our approach uses exploratory search but allows incorporation of prior background knowledge. We validated our approach on one simulated data set, which we compare to the known ground truth, and two real-world data sets for Chronic Fatigue Syndrome and Attention Deficit Hyperactivity Disorder, which we compare to earlier medical studies. The results on the simulated data set show significant improvement over alternative approaches and the results on the real-word data sets show consistency with the hypothesis driven models constructed by medical experts.