 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Love Edge Cases in Formative Math Assessment: Using the AMMORE Dataset and Chain-of-Thought Prompting to Improve Grading Accuracy
Sep 26, 2024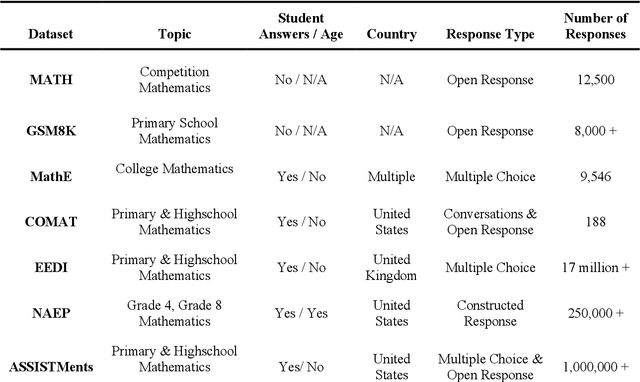
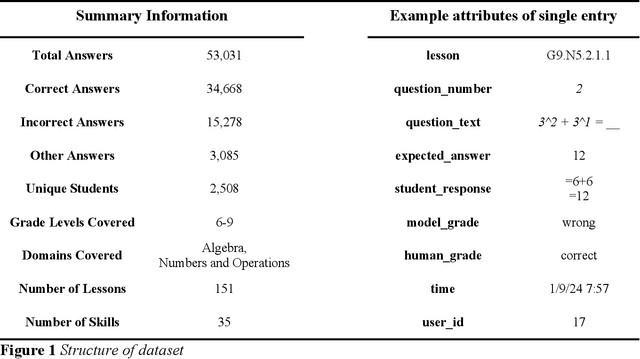


This paper introduces AMMORE, a new dataset of 53,000 math open-response question-answer pairs from Rori, a learning platform used by students in several African countries and conducts two experiments to evaluate the use of large language models (LLM) for grading particularly challenging student answers. The AMMORE dataset enables various potential analyses and provides an important resource for researching student math acquisition in understudied, real-world, educational contexts. In experiment 1 we use a variety of LLM-driven approaches, including zero-shot, few-shot, and chain-of-thought prompting, to grade the 1% of student answers that a rule-based classifier fails to grade accurately. We find that the best-performing approach -- chain-of-thought prompting -- accurately scored 92% of these edge cases, effectively boosting the overall accuracy of the grading from 98.7% to 99.9%. In experiment 2, we aim to better understand the consequential validity of the improved grading accuracy, by passing grades generated by the best-performing LLM-based approach to a Bayesian Knowledge Tracing (BKT) model, which estimated student mastery of specific lessons. We find that relatively modest improvements in model accuracy at the individual question level can lead to significant changes in the estimation of student mastery. Where the rules-based classifier currently used to grade student, answers misclassified the mastery status of 6.9% of students across their completed lessons, using the LLM chain-of-thought approach this misclassification rate was reduced to 2.6% of students. Taken together, these findings suggest that LLMs could be a valuable tool for grading open-response questions in K-12 mathematics education, potentially enabling encouraging wider adoption of open-ended questions in formative assessment.
Using State-of-the-Art Speech Models to Evaluate Oral Reading Fluency in Ghana
Oct 26, 2023This paper reports on a set of three recent experiments utilizing large-scale speech models to evaluate the oral reading fluency (ORF) of students in Ghana. While ORF is a well-established measure of foundational literacy, assessing it typically requires one-on-one sessions between a student and a trained evaluator, a process that is time-consuming and costly. Automating the evaluation of ORF could support better literacy instruction, particularly in education contexts where formative assessment is uncommon due to large class sizes and limited resources. To our knowledge, this research is among the first to examine the use of the most recent versions of large-scale speech models (Whisper V2 wav2vec2.0) for ORF assessment in the Global South. We find that Whisper V2 produces transcriptions of Ghanaian students reading aloud with a Word Error Rate of 13.5. This is close to the model's average WER on adult speech (12.8) and would have been considered state-of-the-art for children's speech transcription only a few years ago. We also find that when these transcriptions are used to produce fully automated ORF scores, they closely align with scores generated by expert human graders, with a correlation coefficient of 0.96. Importantly, these results were achieved on a representative dataset (i.e., students with regional accents, recordings taken in actual classrooms), using a free and publicly available speech model out of the box (i.e., no fine-tuning). This suggests that using large-scale speech models to assess ORF may be feasible to implement and scale in lower-resource, linguistically diverse educational contexts.