 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability to Mark Short Answer Questions in K-12 Education
May 05, 2024

This paper presents reports on a series of experiments with a novel dataset evaluating how well Large Language Models (LLMs) can mark (i.e. grade) open text responses to short answer questions, Specifically, we explore how well different combinations of GPT version and prompt engineering strategies performed at marking real student answers to short answer across different domain areas (Science and History) and grade-levels (spanning ages 5-16) using a new, never-used-before dataset from Carousel, a quizzing platform. We found that GPT-4, with basic few-shot prompting performed well (Kappa, 0.70) and, importantly, very close to human-level performance (0.75). This research builds on prior findings that GPT-4 could reliably score short answer reading comprehension questions at a performance-level very close to that of expert human raters. The proximity to human-level performance, across a variety of subjects and grade levels suggests that LLMs could be a valuable tool for supporting low-stakes formative assessment tasks in K-12 education and has important implications for real-world education delivery.
Using State-of-the-Art Speech Models to Evaluate Oral Reading Fluency in Ghana
Oct 26, 2023This paper reports on a set of three recent experiments utilizing large-scale speech models to evaluate the oral reading fluency (ORF) of students in Ghana. While ORF is a well-established measure of foundational literacy, assessing it typically requires one-on-one sessions between a student and a trained evaluator, a process that is time-consuming and costly. Automating the evaluation of ORF could support better literacy instruction, particularly in education contexts where formative assessment is uncommon due to large class sizes and limited resources. To our knowledge, this research is among the first to examine the use of the most recent versions of large-scale speech models (Whisper V2 wav2vec2.0) for ORF assessment in the Global South. We find that Whisper V2 produces transcriptions of Ghanaian students reading aloud with a Word Error Rate of 13.5. This is close to the model's average WER on adult speech (12.8) and would have been considered state-of-the-art for children's speech transcription only a few years ago. We also find that when these transcriptions are used to produce fully automated ORF scores, they closely align with scores generated by expert human graders, with a correlation coefficient of 0.96. Importantly, these results were achieved on a representative dataset (i.e., students with regional accents, recordings taken in actual classrooms), using a free and publicly available speech model out of the box (i.e., no fine-tuning). This suggests that using large-scale speech models to assess ORF may be feasible to implement and scale in lower-resource, linguistically diverse educational contexts.
Can LLMs Grade Short-answer Reading Comprehension Questions : Foundational Literacy Assessment in LMICs
Oct 26, 2023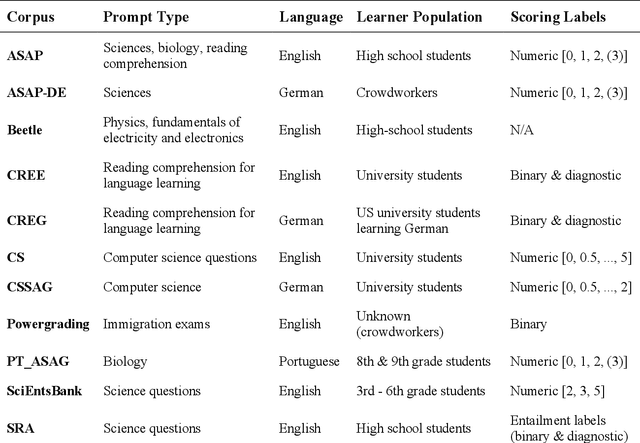



This paper presents emerging evidence of using generative large language models (i.e., GPT-4) to reliably evaluate short-answer reading comprehension questions. Specifically, we explore how various configurations of generative (LLMs) are able to evaluate student responses from a new dataset, drawn from a battery of reading assessments conducted with over 150 students in Ghana. As this dataset is novel and hence not used in training runs of GPT, it offers an opportunity to test for domain shift and evaluate the generalizability of generative LLMs, which are predominantly designed and trained on data from high-income North American countries. We found that GPT-4, with minimal prompt engineering performed extremely well on evaluating the novel dataset (Quadratic Weighted Kappa 0.923, F1 0.88), substantially outperforming transfer-learning based approaches, and even exceeding expert human raters (Quadratic Weighted Kappa 0.915, F1 0.87). To the best of our knowledge, our work is the first to empirically evaluate the performance of generative LLMs on short-answer reading comprehension questions, using real student data, and suggests that generative LLMs have the potential to reliably evaluate foundational literacy. Currently the assessment of formative literacy and numeracy is infrequent in many low and middle-income countries (LMICs) due to the cost and operational complexities of conducting them at scale. Automating the grading process for reading assessment could enable wider usage, and in turn improve decision-making regarding curricula, school management, and teaching practice at the classroom level. Importantly, in contrast transfer learning based approaches, generative LLMs generalize well and the technical barriers to their use are low, making them more feasible to implement and scale in lower resource educational contexts.