 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Grade Short-answer Reading Comprehension Questions : Foundational Literacy Assessment in LMICs
Paper and Code
Oct 26, 2023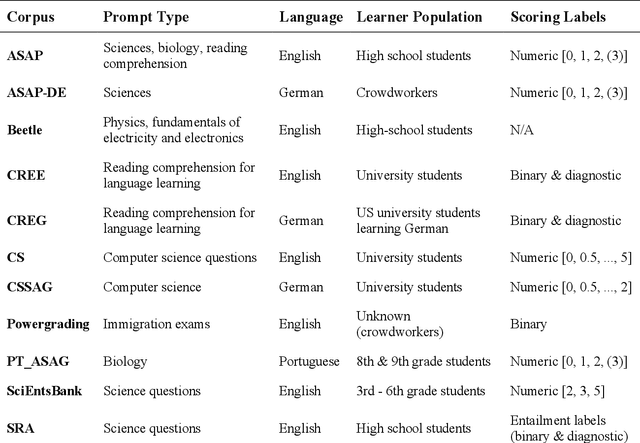



This paper presents emerging evidence of using generative large language models (i.e., GPT-4) to reliably evaluate short-answer reading comprehension questions. Specifically, we explore how various configurations of generative (LLMs) are able to evaluate student responses from a new dataset, drawn from a battery of reading assessments conducted with over 150 students in Ghana. As this dataset is novel and hence not used in training runs of GPT, it offers an opportunity to test for domain shift and evaluate the generalizability of generative LLMs, which are predominantly designed and trained on data from high-income North American countries. We found that GPT-4, with minimal prompt engineering performed extremely well on evaluating the novel dataset (Quadratic Weighted Kappa 0.923, F1 0.88), substantially outperforming transfer-learning based approaches, and even exceeding expert human raters (Quadratic Weighted Kappa 0.915, F1 0.87). To the best of our knowledge, our work is the first to empirically evaluate the performance of generative LLMs on short-answer reading comprehension questions, using real student data, and suggests that generative LLMs have the potential to reliably evaluate foundational literacy. Currently the assessment of formative literacy and numeracy is infrequent in many low and middle-income countries (LMICs) due to the cost and operational complexities of conducting them at scale. Automating the grading process for reading assessment could enable wider usage, and in turn improve decision-making regarding curricula, school management, and teaching practice at the classroom level. Importantly, in contrast transfer learning based approaches, generative LLMs generalize well and the technical barriers to their use are low, making them more feasible to implement and scale in lower resource educational contexts.