 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE: Temporal Incremental Draft Engine for Self-Improving LLM Inference
Feb 05, 2026Speculative decoding can substantially accelerate LLM inference, but realizing its benefits in practice is challenging due to evolving workloads and system-level constraints. We present TIDE (Temporal Incremental Draft Engine), a serving-engine-native framework that integrates online draft adaptation directly into high-performance LLM inference systems. TIDE reuses target model hidden states generated during inference as training signals, enabling zero-overhead draft adaptation without reloading the target model, and employs adaptive runtime control to activate speculation and training only when beneficial. TIDE exploits heterogeneous clusters by mapping decoupled inference and training to appropriate GPU classes. Across diverse real-world workloads, TIDE achieves up to 1.15x throughput improvement over static speculative decoding while reducing draft training time by 1.67x compared to approaches that recompute training signals.
Dynamic Healthcare Embeddings for Improving Patient Care
Mar 21, 2023As hospitals move towards automating and integrating their computing systems, more fine-grained hospital operations data are becoming available. These data include hospital architectural drawings, logs of interactions between patients and healthcare professionals, prescription data, procedures data, and data on patient admission, discharge, and transfers. This has opened up many fascinating avenues for healthcare-related prediction tasks for improving patient care. However, in order to leverage off-the-shelf machine learning software for these tasks, one needs to learn structured representations of entities involved from heterogeneous, dynamic data streams. Here, we propose DECENT, an auto-encoding heterogeneous co-evolving dynamic neural network, for learning heterogeneous dynamic embeddings of patients, doctors, rooms, and medications from diverse data streams. These embeddings capture similarities among doctors, rooms, patients, and medications based on static attributes and dynamic interactions. DECENT enables several applications in healthcare prediction, such as predicting mortality risk and case severity of patients, adverse events (e.g., transfer back into an intensive care unit), and future healthcare-associated infections. The results of using the learned patient embeddings in predictive modeling show that DECENT has a gain of up to 48.1% on the mortality risk prediction task, 12.6% on the case severity prediction task, 6.4% on the medical intensive care unit transfer task, and 3.8% on the Clostridioides difficile (C.diff) Infection (CDI) prediction task over the state-of-the-art baselines. In addition, case studies on the learned doctor, medication, and room embeddings show that our approach learns meaningful and interpretable embeddings.
D-TensoRF: Tensorial Radiance Fields for Dynamic Scenes
Dec 06, 2022


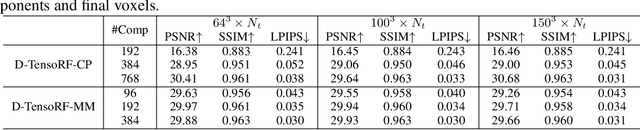
Neural radiance field (NeRF) attracts attention as a promising approach to reconstructing the 3D scene. As NeRF emerges, subsequent studies have been conducted to model dynamic scenes, which include motions or topological changes. However, most of them use an additional deformation network, slowing down the training and rendering speed. Tensorial radiance field (TensoRF) recently shows its potential for fast, high-quality reconstruction of static scenes with compact model size. In this paper, we present D-TensoRF, a tensorial radiance field for dynamic scenes, enabling novel view synthesis at a specific time. We consider the radiance field of a dynamic scene as a 5D tensor. The 5D tensor represents a 4D grid in which each axis corresponds to X, Y, Z, and time and has 1D multi-channel features per element. Similar to TensoRF, we decompose the grid either into rank-one vector components (CP decomposition) or low-rank matrix components (newly proposed MM decomposition). We also use smoothing regularization to reflect the relationship between features at different times (temporal dependency). We conduct extensive evaluations to analyze our models. We show that D-TensoRF with CP decomposition and MM decomposition both have short training times and significantly low memory footprints with quantitatively and qualitatively competitive rendering results in comparison to the state-of-the-art methods in 3D dynamic scene modeling.