 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Sparse Feature Selection in Communication-Restricted Networks
Nov 02, 2021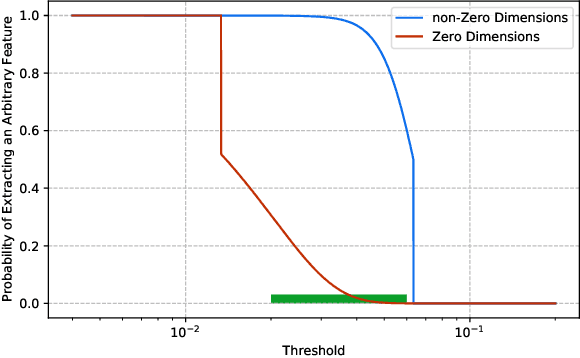
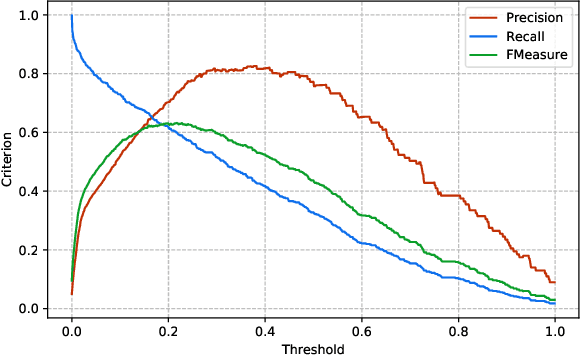
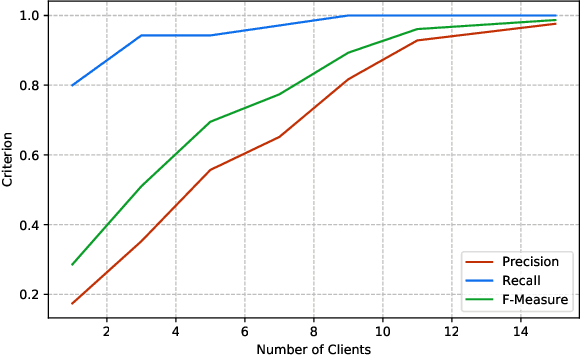
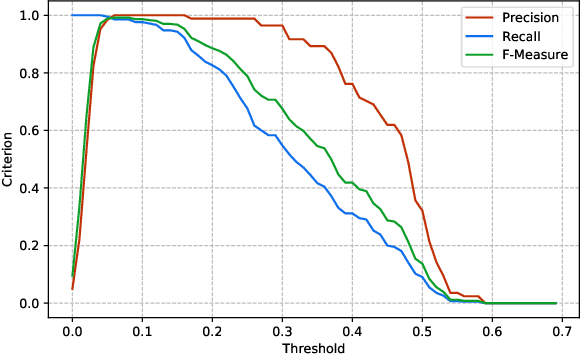
This paper aims to propose and theoretically analyze a new distributed scheme for sparse linear regression and feature selection. The primary goal is to learn the few causal features of a high-dimensional dataset based on noisy observations from an unknown sparse linear model. However, the presumed training set which includes $n$ data samples in $\mathbb{R}^p$ is already distributed over a large network with $N$ clients connected through extremely low-bandwidth links. Also, we consider the asymptotic configuration of $1\ll N\ll n\ll p$. In order to infer the causal dimensions from the whole dataset, we propose a simple, yet effective method for information sharing in the network. In this regard, we theoretically show that the true causal features can be reliably recovered with negligible bandwidth usage of $O\left(N\log p\right)$ across the network. This yields a significantly lower communication cost in comparison with the trivial case of transmitting all the samples to a single node (centralized scenario), which requires $O\left(np\right)$ transmissions. Even more sophisticated schemes such as ADMM still have a communication complexity of $O\left(Np\right)$. Surprisingly, our sample complexity bound is proved to be the same (up to a constant factor) as the optimal centralized approach for a fixed performance measure in each node, while that of a na\"{i}ve decentralized technique grows linearly with $N$. Theoretical guarantees in this paper are based on the recent analytic framework of debiased LASSO in Javanmard et al. (2019), and are supported by several computer experiments performed on both synthetic and real-world datasets.