 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAFX: A General Audio Feature eXtractor
Jul 19, 2022



Most machine learning models for audio tasks are dealing with a handcrafted feature, the spectrogram. However, it is still unknown whether the spectrogram could be replaced with deep learning based features. In this paper, we answer this question by comparing the different learnable neural networks extracting features with a successful spectrogram model and proposed a General Audio Feature eXtractor (GAFX) based on a dual U-Net (GAFX-U), ResNet (GAFX-R), and Attention (GAFX-A) modules. We design experiments to evaluate this model on the music genre classification task on the GTZAN dataset and perform a detailed ablation study of different configurations of our framework and our model GAFX-U, following the Audio Spectrogram Transformer (AST) classifier achieves competitive performance.
Audio Input Generates Continuous Frames to Synthesize Facial Video Using Generative Adiversarial Networks
Jul 18, 2022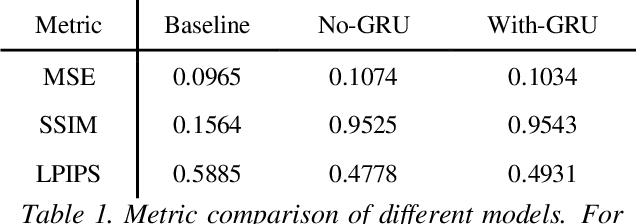
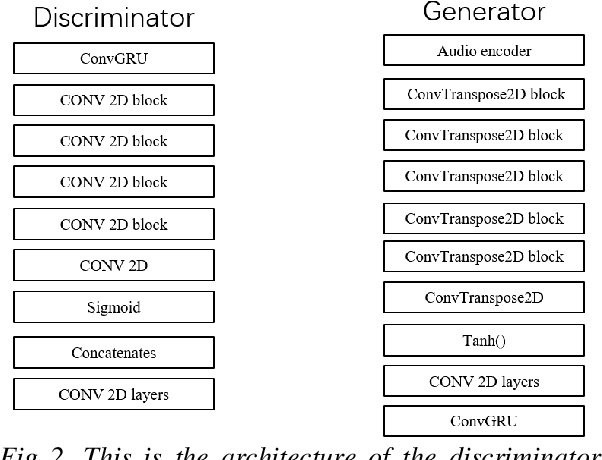

This paper presents a simple method for speech videos generation based on audio: given a piece of audio, we can generate a video of the target face speaking this audio. We propose Generative Adversarial Networks (GAN) with cut speech audio input as condition and use Convolutional Gate Recurrent Unit (GRU) in generator and discriminator. Our model is trained by exploiting the short audio and the frames in this duration. For training, we cut the audio and extract the face in the corresponding frames. We designed a simple encoder and compare the generated frames using GAN with and without GRU. We use GRU for temporally coherent frames and the results show that short audio can produce relatively realistic output results.