Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Input Generates Continuous Frames to Synthesize Facial Video Using Generative Adiversarial Networks
Paper and Code
Jul 18, 2022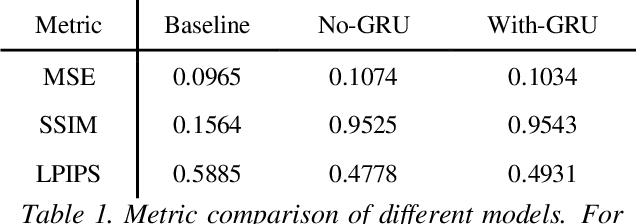
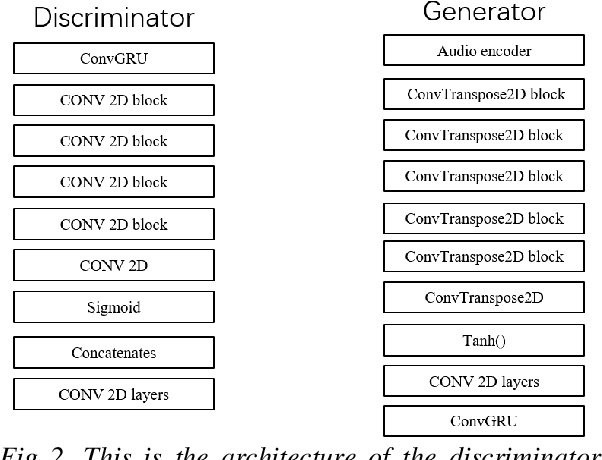
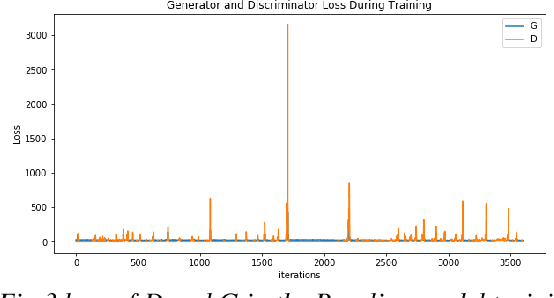

This paper presents a simple method for speech videos generation based on audio: given a piece of audio, we can generate a video of the target face speaking this audio. We propose Generative Adversarial Networks (GAN) with cut speech audio input as condition and use Convolutional Gate Recurrent Unit (GRU) in generator and discriminator. Our model is trained by exploiting the short audio and the frames in this duration. For training, we cut the audio and extract the face in the corresponding frames. We designed a simple encoder and compare the generated frames using GAN with and without GRU. We use GRU for temporally coherent frames and the results show that short audio can produce relatively realistic output results.
* 5 pages, 5 figures
View paper on