 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergent Actor-Critic Algorithms Under Off-Policy Training and Function Approximation
Feb 21, 2018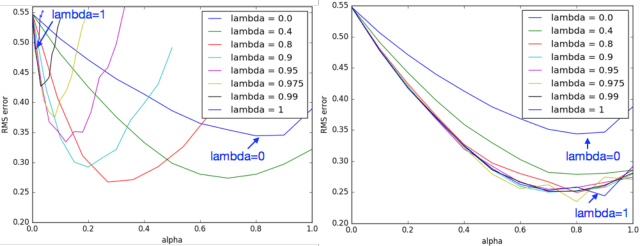
We present the first class of policy-gradient algorithms that work with both state-value and policy function-approximation, and are guaranteed to converge under off-policy training. Our solution targets problems in reinforcement learning where the action representation adds to the-curse-of-dimensionality; that is, with continuous or large action sets, thus making it infeasible to estimate state-action value functions (Q functions). Using state-value functions helps to lift the curse and as a result naturally turn our policy-gradient solution into classical Actor-Critic architecture whose Actor uses state-value function for the update. Our algorithms, Gradient Actor-Critic and Emphatic Actor-Critic, are derived based on the exact gradient of averaged state-value function objective and thus are guaranteed to converge to its optimal solution, while maintaining all the desirable properties of classical Actor-Critic methods with no additional hyper-parameters. To our knowledge, this is the first time that convergent off-policy learning methods have been extended to classical Actor-Critic methods with function approximation.
Optimal Demand Response Using Device Based Reinforcement Learning
Jun 28, 2014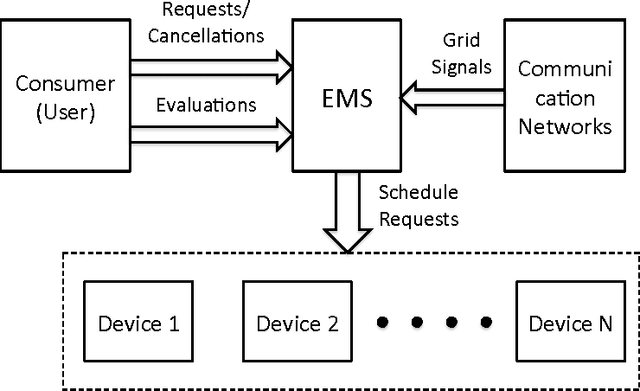
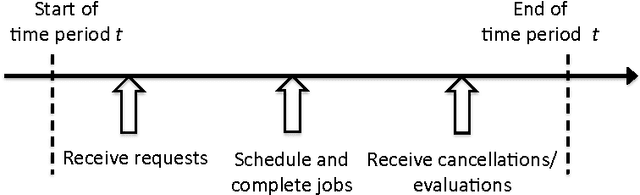
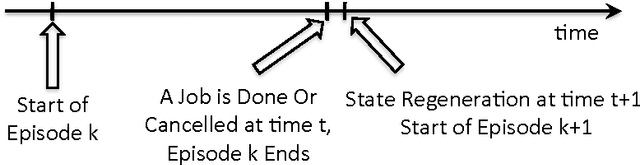
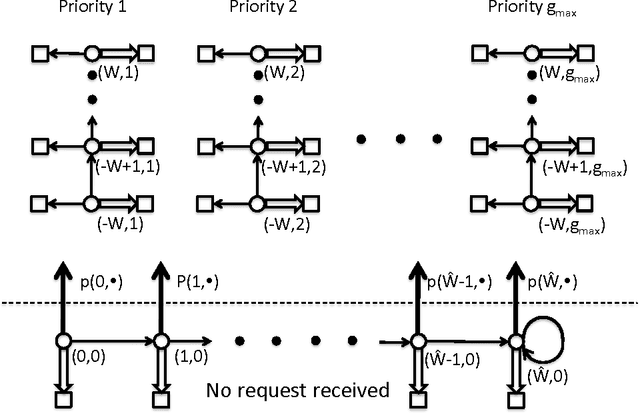
Demand response (DR) for residential and small commercial buildings is estimated to account for as much as 65% of the total energy savings potential of DR, and previous work shows that a fully automated Energy Management System (EMS) is a necessary prerequisite to DR in these areas. In this paper, we propose a novel EMS formulation for DR problems in these sectors. Specifically, we formulate a fully automated EMS's rescheduling problem as a reinforcement learning (RL) problem, and argue that this RL problem can be approximately solved by decomposing it over device clusters. Compared with existing formulations, our new formulation (1) does not require explicitly modeling the user's dissatisfaction on job rescheduling, (2) enables the EMS to self-initiate jobs, (3) allows the user to initiate more flexible requests and (4) has a computational complexity linear in the number of devices. We also demonstrate the simulation results of applying Q-learning, one of the most popular and classical RL algorithms, to a representative example.