 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Recursive Ranking Grouping for Large Scale Global Optimization
Jun 08, 2022



Real-world optimization problems may have a different underlying structure. In black-box optimization, the dependencies between decision variables remain unknown. However, some techniques can discover such interactions accurately. In Large Scale Global Optimization (LSGO), problems are high-dimensional. It was shown effective to decompose LSGO problems into subproblems and optimize them separately. The effectiveness of such approaches may be highly dependent on the accuracy of problem decomposition. Many state-of-the-art decomposition strategies are derived from Differential Grouping (DG). However, if a given problem consists of non-additively separable subproblems, their ability to detect only true interactions might decrease significantly. Therefore, we propose Incremental Recursive Ranking Grouping (IRRG) that does not suffer from this flaw. IRRG consumes more fitness function evaluations than the recent DG-based propositions, e.g., Recursive DG 3 (RDG3). Nevertheless, the effectiveness of the considered Cooperative Co-evolution frameworks after embedding IRRG or RDG3 was similar for problems with additively separable subproblems that are suitable for RDG3. However, after replacing the additive separability with non-additive, embedding IRRG leads to results of significantly higher quality.
Generating Object Cluster Hierarchies for Benchmarking
Jun 17, 2016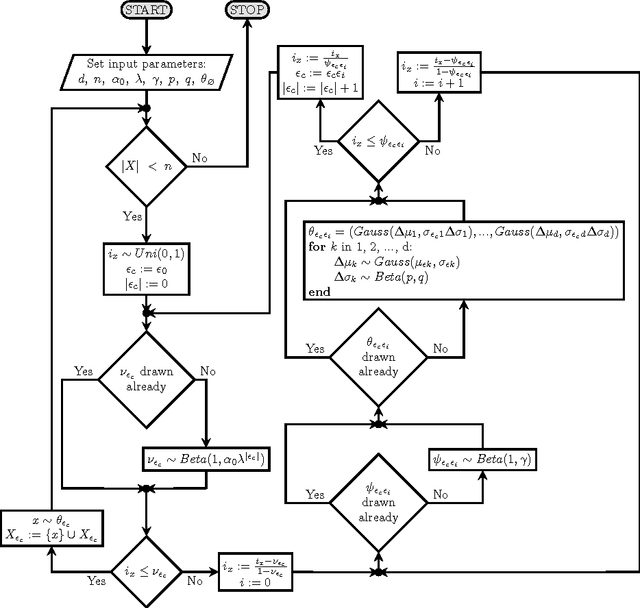

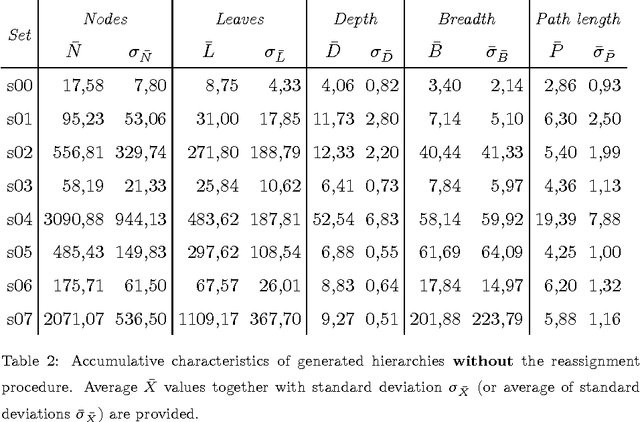

The field of Machine Learning and the topic of clustering within it is still widely researched. Recently, researchers became interested in a new variant of hierarchical clustering, where hierarchical (partial order) relationships exist not only between clusters but also objects. In this variant of clustering, objects can be assigned not only to leave, but other properties are also defined. Although examples of this approach already exist in literature, the authors have encountered a problem with the analysis and comparison of obtained results. The problem is twofold. Firstly, there is a lack of evaluation methods. Secondly, there is a lack of available benchmark data, at least the authors failed to find them. The aim of this work is to fill the second gap. The main contribution of this paper is a new method of generating hierarchical structures of data. Additionally, the paper includes a theoretical analysis of the generation parameters and their influence on the results. Comprehensive experiments are presented and discussed. The dataset generator and visualiser tools developed are publicly available for use (http://kio.pwr.edu.pl/?page_id=396).