 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Fairly Classify the Quality of Wireless Links
Feb 24, 2021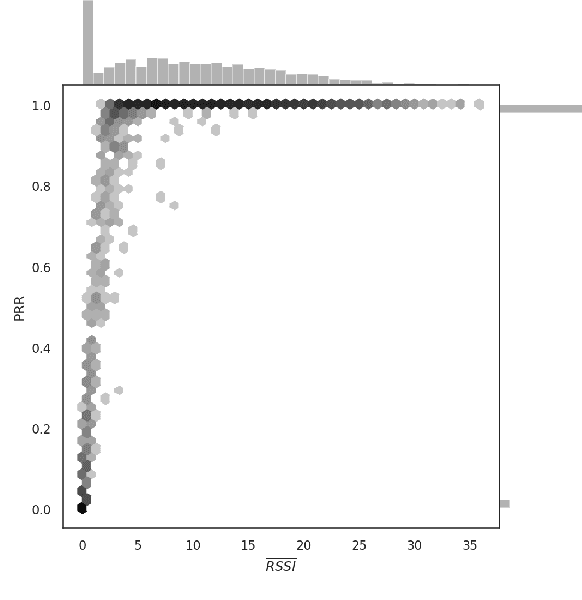
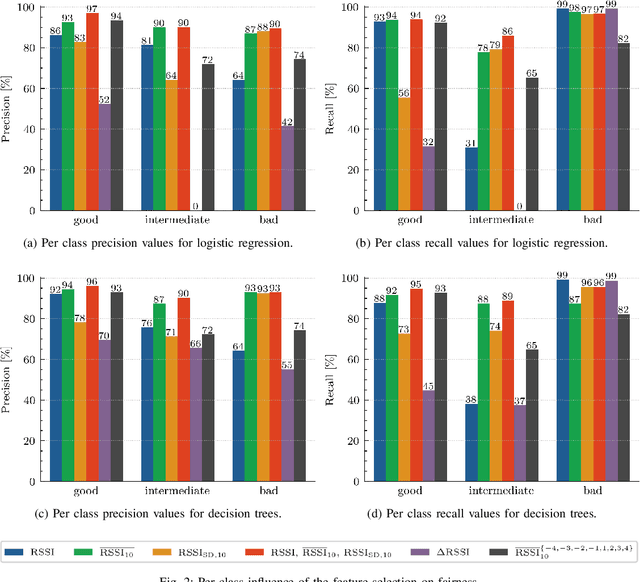
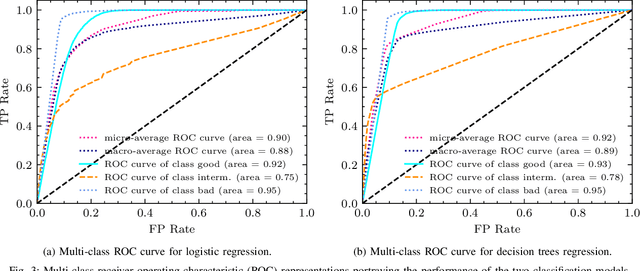

Machine learning (ML) has been used to develop increasingly accurate link quality estimators for wireless networks. However, more in-depth questions regarding the most suitable class of models, most suitable metrics and model performance on imbalanced datasets remain open. In this paper, we propose a new tree-based link quality classifier that meets high performance and fairly classifies the minority class and, at the same time, incurs low training cost. We compare the tree-based model, to a multilayer perceptron (MLP) non-linear model and two linear models, namely logistic regression (LR) and SVM, on a selected imbalanced dataset and evaluate their results using five different performance metrics. Our study shows that 1) non-linear models perform slightly better than linear models in general, 2) the proposed non-linear tree-based model yields the best performance trade-off considering F1, training time and fairness, 3) single metric aggregated evaluations based only on accuracy can hide poor, unfair performance especially on minority classes, and 4) it is possible to improve the performance on minority classes, by over 40% through feature selection and by over 20% through resampling, therefore leading to fairer classification results.
Learning to Detect Anomalous Wireless Links in IoT Networks
Aug 12, 2020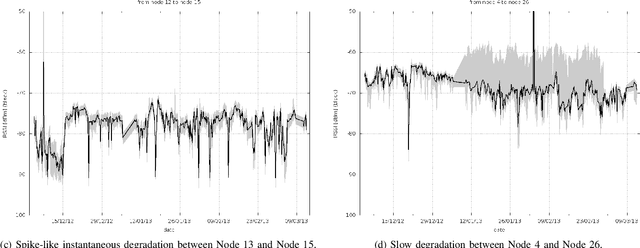
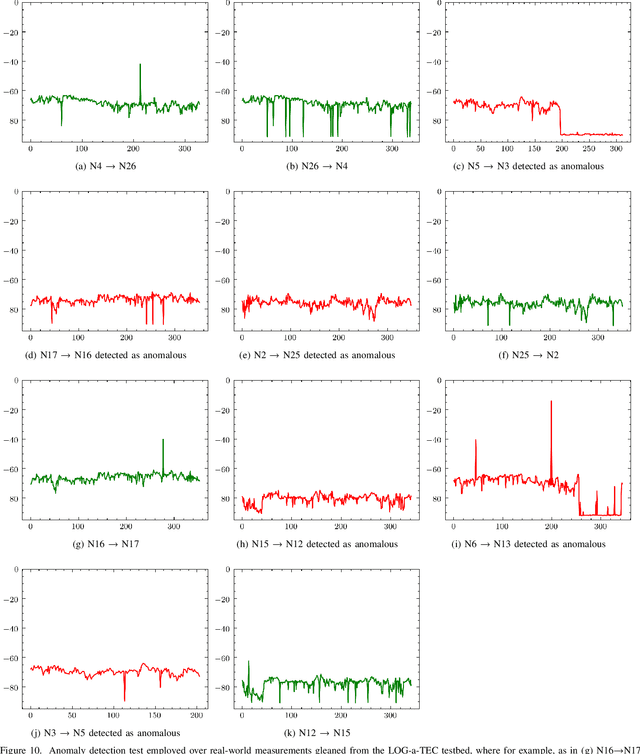
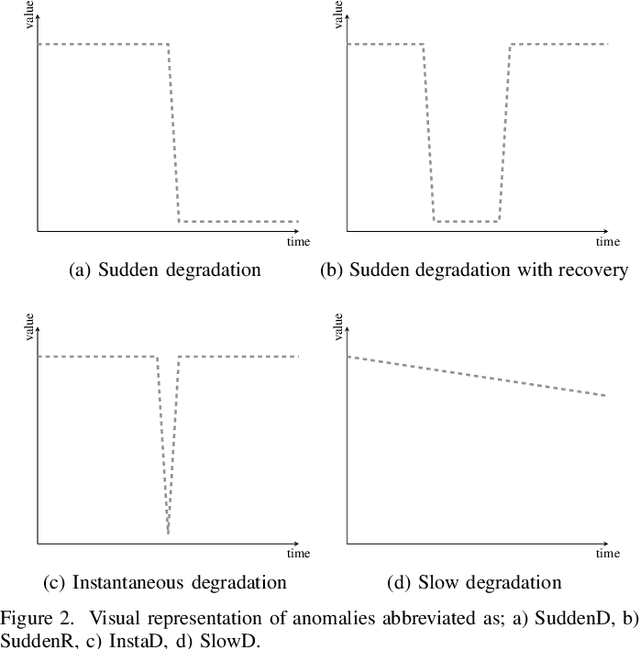
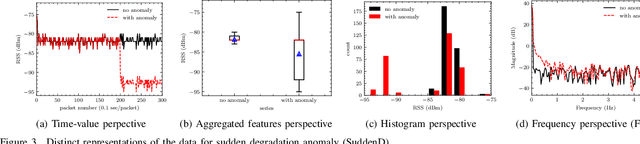
After decades of research, Internet of Things (IoT) is finally permeating real-life and helps improve the efficiency of infrastructures and processes as well as our health. As massive number of IoT devices are deployed, they naturally incurs great operational costs to ensure intended operations. To effectively handle such intended operations in massive IoT networks, automatic detection of malfunctioning, namely anomaly detection, becomes a critical but challenging task. In this paper, motivated by a real-world experimental IoT deployment, we introduce four types of wireless network anomalies that are identified at the link layer. We study the performance of threshold- and machine learning (ML)-based classifiers to automatically detect these anomalies. We examine the relative performance of three supervised and three unsupervised ML techniques on both non-encoded and encoded (autoencoder) feature representations. Our results demonstrate that; i) automatically generated features using autoencoders significantly outperform the non-encoded representations and can improve F1 score up to 500% and ii) among the best performing models based on F1 score, supervised ML models outperform the unsupervised counterpart models with about 18% on average for anomaly types SuddenD and SuddenR, and this trend also applies to SlowD and InstaD anomalies, albeit with a tiny margin.