 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIQI: Perceptual Image Quality Index based on Ensemble of Gaussian Process Regression
May 16, 2023Digital images contain a lot of redundancies, therefore, compression techniques are applied to reduce the image size without loss of reasonable image quality. Same become more prominent in the case of videos which contains image sequences and higher compression ratios are achieved in low throughput networks. Assessment of quality of images in such scenarios has become of particular interest. Subjective evaluation in most of the scenarios is infeasible so objective evaluation is preferred. Among the three objective quality measures, full-reference and reduced-reference methods require an original image in some form to calculate the image quality which is unfeasible in scenarios such as broadcasting, acquisition or enhancement. Therefore, a no-reference Perceptual Image Quality Index (PIQI) is proposed in this paper to assess the quality of digital images which calculates luminance and gradient statistics along with mean subtracted contrast normalized products in multiple scales and color spaces. These extracted features are provided to a stacked ensemble of Gaussian Process Regression (GPR) to perform the perceptual quality evaluation. The performance of the PIQI is checked on six benchmark databases and compared with twelve state-of-the-art methods and competitive results are achieved. The comparison is made based on RMSE, Pearson and Spearman correlation coefficients between ground truth and predicted quality scores. The scores of 0.0552, 0.9802 and 0.9776 are achieved respectively for these metrics on CSIQ database. Two cross-dataset evaluation experiments are performed to check the generalization of PIQI.
Image Quality Assessment for Foliar Disease Identification (AgroPath)
Sep 26, 2022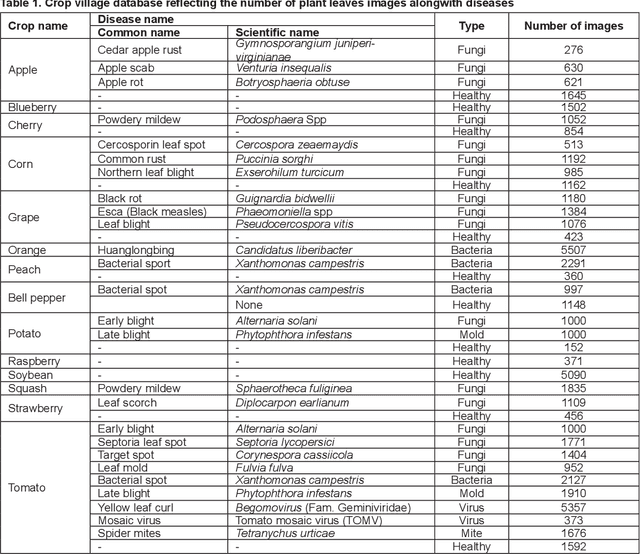
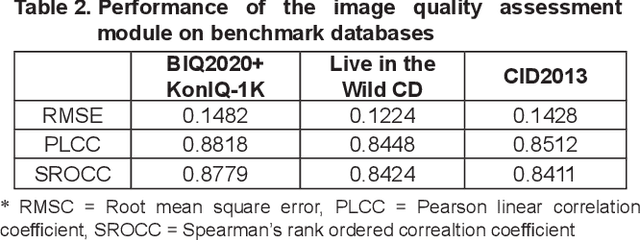
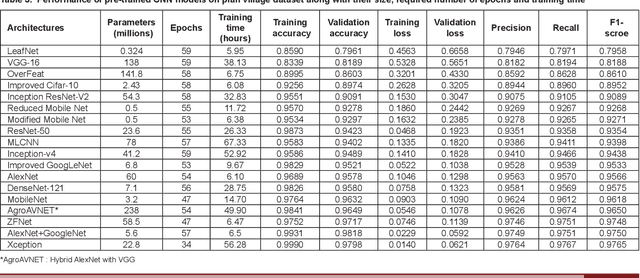
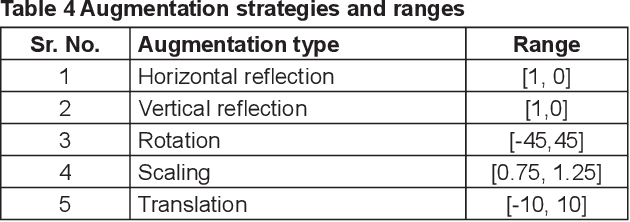
Crop diseases are a major threat to food security and their rapid identification is important to prevent yield loss. Swift identification of these diseases are difficult due to the lack of necessary infrastructure. Recent advances in computer vision and increasing penetration of smartphones have paved the way for smartphone-assisted disease identification. Most of the plant diseases leave particular artifacts on the foliar structure of the plant. This study was conducted in 2020 at Department of Computer Science and Engineering, University of Engineering and Technology, Lahore, Pakistan to check leaf-based plant disease identification. This study provided a deep neural network-based solution to foliar disease identification and incorporated image quality assessment to select the image of the required quality to perform identification and named it Agricultural Pathologist (Agro Path). The captured image by a novice photographer may contain noise, lack of structure, and blur which result in a failed or inaccurate diagnosis. Moreover, AgroPath model had 99.42% accuracy for foliar disease identification. The proposed addition can be especially useful for application of foliar disease identification in the field of agriculture.
Non-Reference Quality Monitoring of Digital Images using Gradient Statistics and Feedforward Neural Networks
Dec 27, 2021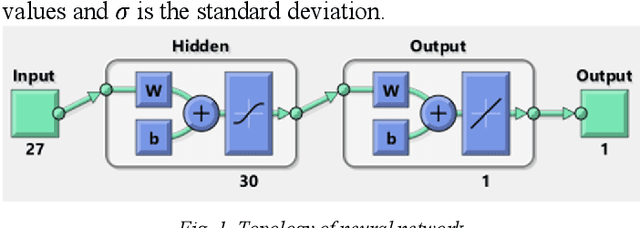
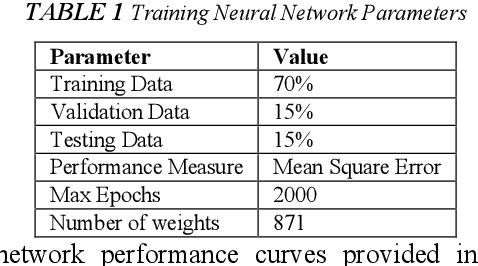
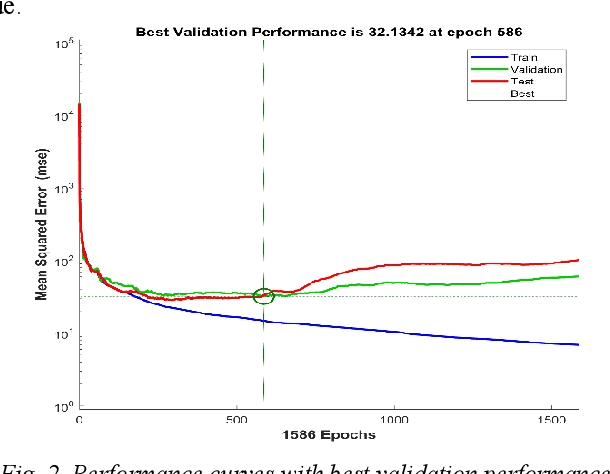
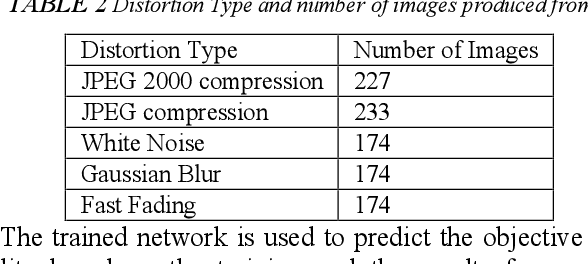
Digital images contain a lot of redundancies, therefore, compressions are applied to reduce the image size without the loss of reasonable image quality. The same become more prominent in the case of videos that contains image sequences and higher compression ratios are achieved in low throughput networks. Assessment of the quality of images in such scenarios becomes of particular interest. Subjective evaluation in most of the scenarios becomes infeasible so objective evaluation is preferred. Among the three objective quality measures, full-reference and reduced-reference methods require an original image in some form to calculate the quality score which is not feasible in scenarios such as broadcasting or IP video. Therefore, a non-reference quality metric is proposed to assess the quality of digital images which calculates luminance and multiscale gradient statistics along with mean subtracted contrast normalized products as features to train a Feedforward Neural Network with Scaled Conjugate Gradient. The trained network has provided good regression and R2 measures and further testing on LIVE Image Quality Assessment database release-2 has shown promising results. Pearson, Kendall, and Spearman's correlation are calculated between predicted and actual quality scores and their results are comparable to the state-of-the-art systems. Moreover, the proposed metric is computationally faster than its counterparts and can be used for the quality assessment of image sequences.
Development of Crop Yield Estimation Model using Soil and Environmental Parameters
Feb 10, 2021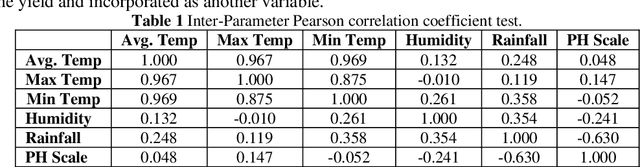
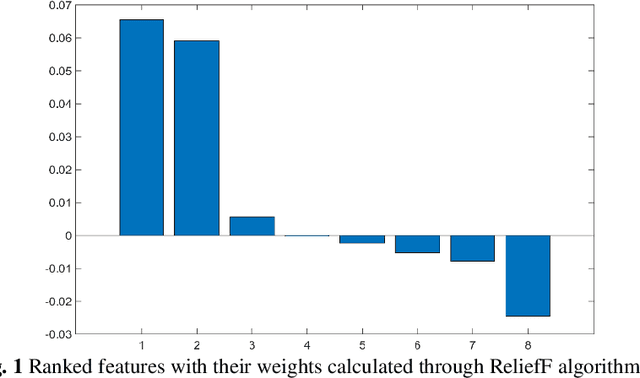

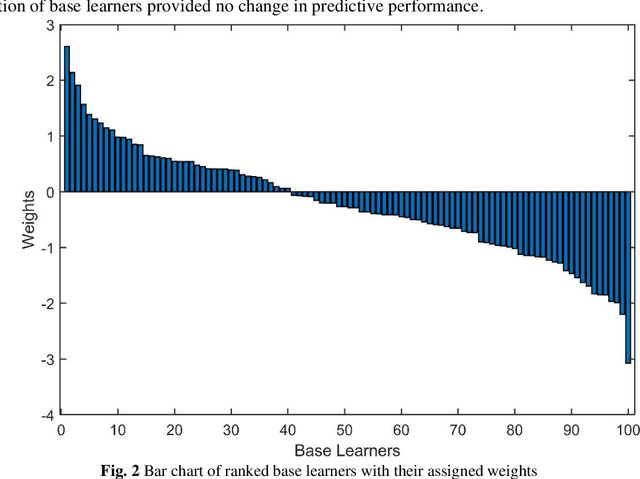
Crop yield is affected by various soil and environmental parameters and can vary significantly. Therefore, a crop yield estimation model which can predict pre-harvest yield is required for food security. The study is conducted on tea forms operating under National Tea Research Institute, Pakistan. The data is recorded on monthly basis for ten years period. The parameters collected are minimum and maximum temperature, humidity, rainfall, PH level of the soil, usage of pesticide and labor expertise. The design of model incorporated all of these parameters and identified the parameters which are most crucial for yield predictions. Feature transformation is performed to obtain better performing model. The designed model is based on an ensemble of neural networks and provided an R-squared of 0.9461 and RMSE of 0.1204 indicating the usability of the proposed model in yield forecasting based on surface and environmental parameters.
* crop yield forecasting, regression, data mining, artificial neural network, ensemble learning
Leaf Image-based Plant Disease Identification using Color and Texture Features
Feb 08, 2021
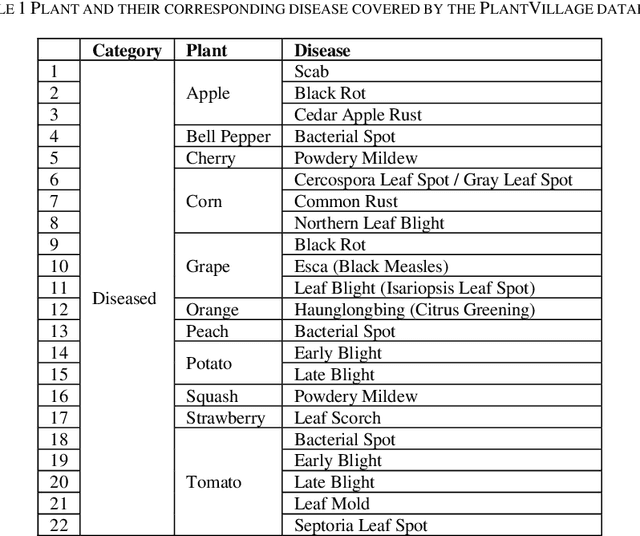

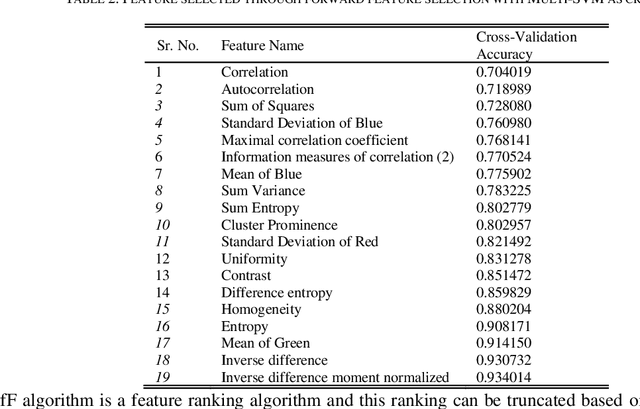
Identification of plant disease is usually done through visual inspection or during laboratory examination which causes delays resulting in yield loss by the time identification is complete. On the other hand, complex deep learning models perform the task with reasonable performance but due to their large size and high computational requirements, they are not suited to mobile and handheld devices. Our proposed approach contributes automated identification of plant diseases which follows a sequence of steps involving pre-processing, segmentation of diseased leaf area, calculation of features based on the Gray-Level Co-occurrence Matrix (GLCM), feature selection and classification. In this study, six color features and twenty-two texture features have been calculated. Support vector machines is used to perform one-vs-one classification of plant disease. The proposed model of disease identification provides an accuracy of 98.79% with a standard deviation of 0.57 on 10-fold cross-validation. The accuracy on a self-collected dataset is 82.47% for disease identification and 91.40% for healthy and diseased classification. The reported performance measures are better or comparable to the existing approaches and highest among the feature-based methods, presenting it as the most suitable method to automated leaf-based plant disease identification. This prototype system can be extended by adding more disease categories or targeting specific crop or disease categories.