 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Implementing Energy-aware Data-driven Intelligence for Smart Health Applications on Mobile Platforms
Feb 01, 2023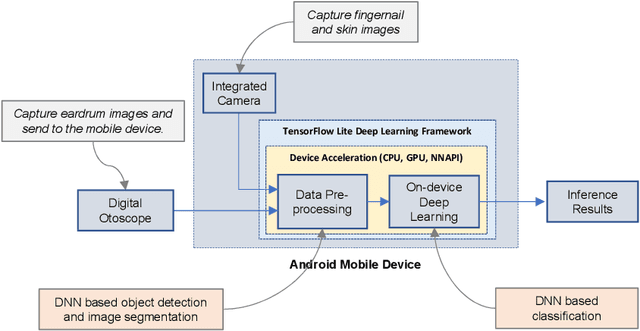

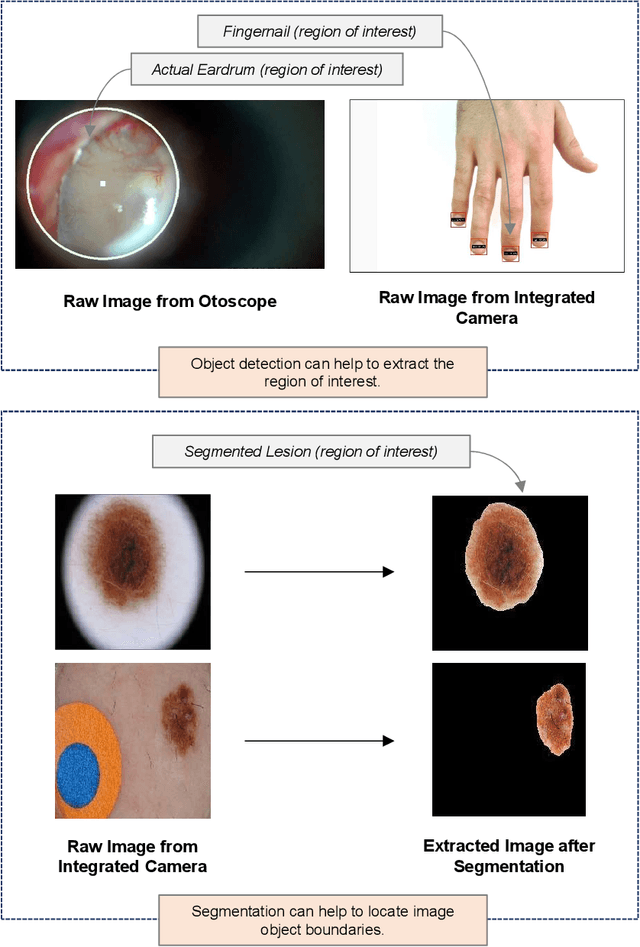

Recent breakthrough technological progressions of powerful mobile computing resources such as low-cost mobile GPUs along with cutting-edge, open-source software architectures have enabled high-performance deep learning on mobile platforms. These advancements have revolutionized the capabilities of today's mobile applications in different dimensions to perform data-driven intelligence locally, particularly for smart health applications. Unlike traditional machine learning (ML) architectures, modern on-device deep learning frameworks are proficient in utilizing computing resources in mobile platforms seamlessly, in terms of producing highly accurate results in less inference time. However, on the flip side, energy resources in a mobile device are typically limited. Hence, whenever a complex Deep Neural Network (DNN) architecture is fed into the on-device deep learning framework, while it achieves high prediction accuracy (and performance), it also urges huge energy demands during the runtime. Therefore, managing these resources efficiently within the spectrum of performance and energy efficiency is the newest challenge for any mobile application featuring data-driven intelligence beyond experimental evaluations. In this paper, first, we provide a timely review of recent advancements in on-device deep learning while empirically evaluating the performance metrics of current state-of-the-art ML architectures and conventional ML approaches with the emphasis given on energy characteristics by deploying them on a smart health application. With that, we are introducing a new framework through an energy-aware, adaptive model comprehension and realization (EAMCR) approach that can be utilized to make more robust and efficient inference decisions based on the available computing/energy resources in the mobile device during the runtime.
Generating Black-Box Adversarial Examples in Sparse Domain
Jan 22, 2021
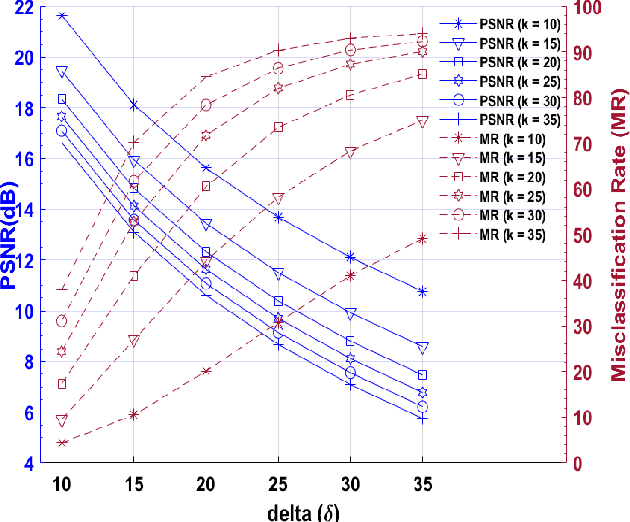
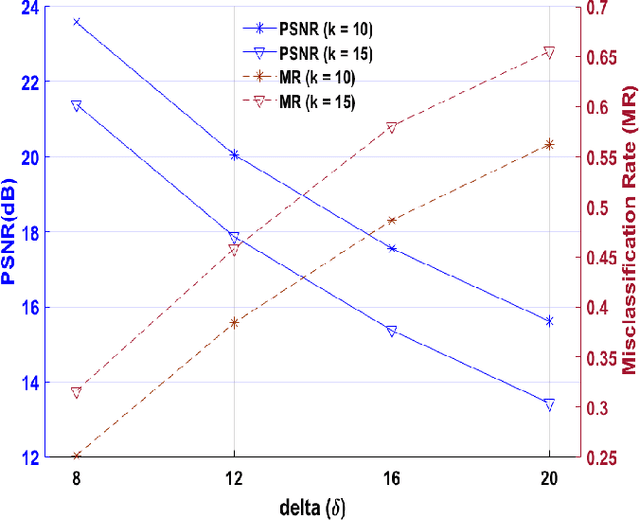

Applications of machine learning (ML) models and convolutional neural networks (CNNs) have been rapidly increased. Although ML models provide high accuracy in many applications, recent investigations show that such networks are highly vulnerable to adversarial attacks. The black-box adversarial attack is one type of attack that the attacker does not have any knowledge about the model or the training dataset. In this paper, we propose a novel approach to generate a black-box attack in sparse domain whereas the most important information of an image can be observed. Our investigation shows that large sparse components play a critical role in the performance of the image classifiers. Under this presumption, to generate adversarial example, we transfer an image into a sparse domain and put a threshold to choose only k largest components. In contrast to the very recent works that randomly perturb k low frequency (LoF) components, we perturb k largest sparse (LaS)components either randomly (query-based) or in the direction of the most correlated sparse signal from a different class. We show that LaS components contain some middle or higher frequency components information which can help us fool the classifiers with a fewer number of queries. We also demonstrate the effectiveness of this approach by fooling the TensorFlow Lite (TFLite) model of Google Cloud Vision platform. Mean squared error (MSE) and peak signal to noise ratio (PSNR) are used as quality metrics. We present a theoretical proof to connect these metrics to the level of perturbation in the sparse domain. We tested our adversarial examples to the state-of-the-art CNNs and support vector machine (SVM) classifiers on color and grayscale image datasets. The results show the proposed method can highly increase the misclassification rate of the classifiers.