 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Black-Box Adversarial Examples in Sparse Domain
Paper and Code
Jan 22, 2021
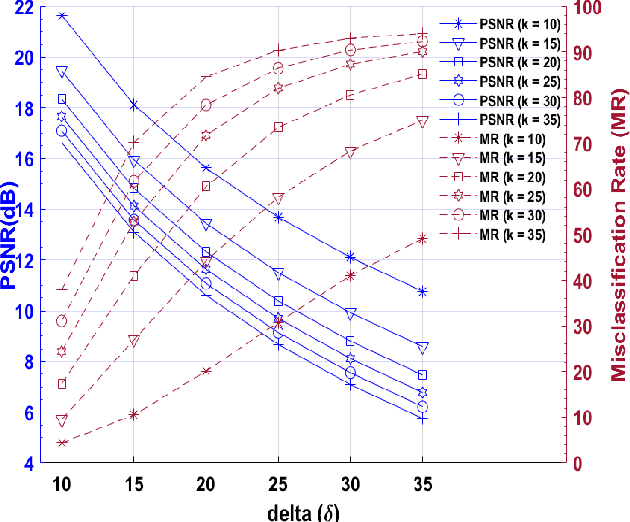
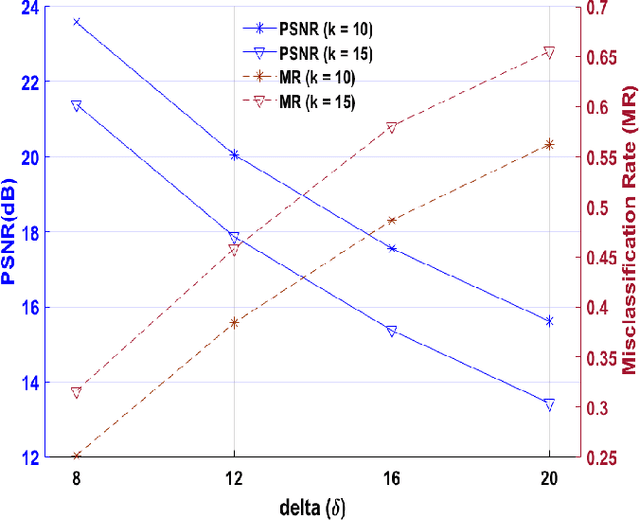

Applications of machine learning (ML) models and convolutional neural networks (CNNs) have been rapidly increased. Although ML models provide high accuracy in many applications, recent investigations show that such networks are highly vulnerable to adversarial attacks. The black-box adversarial attack is one type of attack that the attacker does not have any knowledge about the model or the training dataset. In this paper, we propose a novel approach to generate a black-box attack in sparse domain whereas the most important information of an image can be observed. Our investigation shows that large sparse components play a critical role in the performance of the image classifiers. Under this presumption, to generate adversarial example, we transfer an image into a sparse domain and put a threshold to choose only k largest components. In contrast to the very recent works that randomly perturb k low frequency (LoF) components, we perturb k largest sparse (LaS)components either randomly (query-based) or in the direction of the most correlated sparse signal from a different class. We show that LaS components contain some middle or higher frequency components information which can help us fool the classifiers with a fewer number of queries. We also demonstrate the effectiveness of this approach by fooling the TensorFlow Lite (TFLite) model of Google Cloud Vision platform. Mean squared error (MSE) and peak signal to noise ratio (PSNR) are used as quality metrics. We present a theoretical proof to connect these metrics to the level of perturbation in the sparse domain. We tested our adversarial examples to the state-of-the-art CNNs and support vector machine (SVM) classifiers on color and grayscale image datasets. The results show the proposed method can highly increase the misclassification rate of the classifiers.