 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning with incomplete datasets using multi-objective optimization models
Dec 04, 2020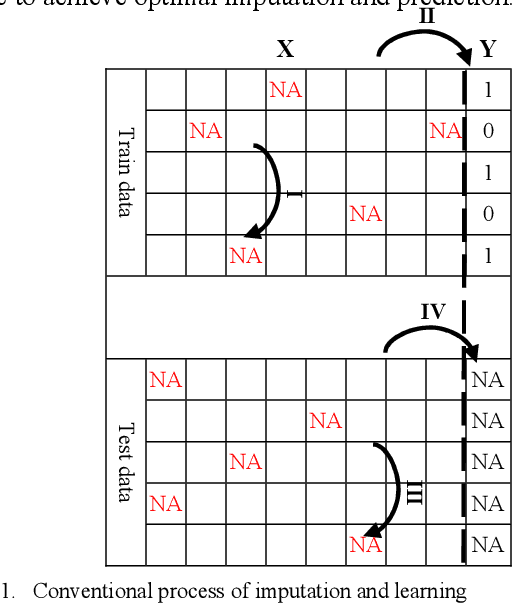
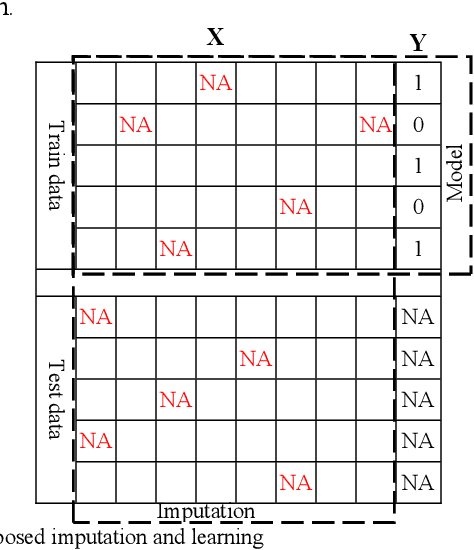
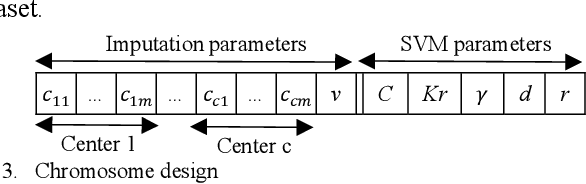
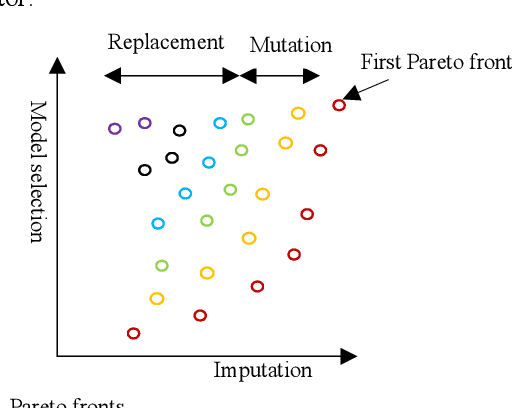
Machine learning techniques have been developed to learn from complete data. When missing values exist in a dataset, the incomplete data should be preprocessed separately by removing data points with missing values or imputation. In this paper, we propose an online approach to handle missing values while a classification model is learnt. To reach this goal, we develop a multi-objective optimization model with two objective functions for imputation and model selection. We also propose three formulations for imputation objective function. We use an evolutionary algorithm based on NSGA II to find the optimal solutions as the Pareto solutions. We investigate the reliability and robustness of the proposed model using experiments by defining several scenarios in dealing with missing values and classification. We also describe how the proposed model can contribute to medical informatics. We compare the performance of three different formulations via experimental results. The proposed model results get validated by comparing with a comparable literature.
Multicriteria Group Decision-Making Under Uncertainty Using Interval Data and Cloud Models
Dec 01, 2020In this study, we propose a multicriteria group decision making (MCGDM) algorithm under uncertainty where data is collected as intervals. The proposed MCGDM algorithm aggregates the data, determines the optimal weights for criteria and ranks alternatives with no further input. The intervals give flexibility to experts in assessing alternatives against criteria and provide an opportunity to gain maximum information. We also propose a novel method to aggregate expert judgements using cloud models. We introduce an experimental approach to check the validity of the aggregation method. After that, we use the aggregation method for an MCGDM problem. Here, we find the optimal weights for each criterion by proposing a bilevel optimisation model. Then, we extend the technique for order of preference by similarity to ideal solution (TOPSIS) for data based on cloud models to prioritise alternatives. As a result, the algorithm can gain information from decision makers with different levels of uncertainty and examine alternatives with no more information from decision-makers. The proposed MCGDM algorithm is implemented on a case study of a cybersecurity problem to illustrate its feasibility and effectiveness. The results verify the robustness and validity of the proposed MCGDM using sensitivity analysis and comparison with other existing algorithms.
Synthetic Over-sampling with the Minority and Majority classes for imbalance problems
Nov 09, 2020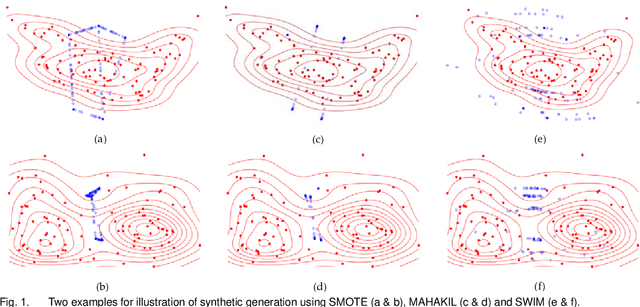

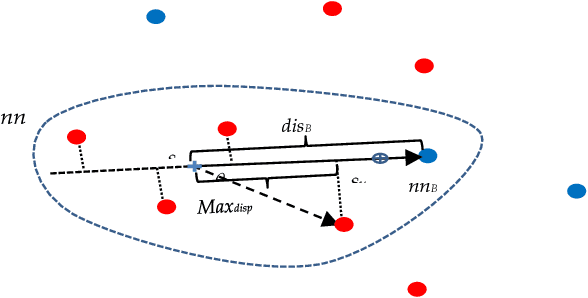

Class imbalance is a substantial challenge in classifying many real-world cases. Synthetic over-sampling methods have been effective to improve the performance of classifiers for imbalance problems. However, most synthetic over-sampling methods generate non-diverse synthetic instances within the convex hull formed by the existing minority instances as they only concentrate on the minority class and ignore the vast information provided by the majority class. They also often do not perform well for extremely imbalanced data as the fewer the minority instances, the less information to generate synthetic instances. Moreover, existing methods that generate synthetic instances using distributional information of the majority class cannot perform effectively when the majority class has a multi-modal distribution. We propose a new method to generate diverse and adaptable synthetic instances using Synthetic Over-sampling with the Minority and Majority classes (SOMM). SOMM generates synthetic instances diversely within the minority data space. It updates the generated instances adaptively to the neighbourhood including both classes. Thus, SOMM performs well for both binary and multiclass imbalance problems. We examine the performance of SOMM for binary and multiclass problems using benchmark data sets for different imbalance levels. The empirical results show the superiority of SOMM compared to other existing methods.