 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Matrix Factorization Model for Hellinger-based Trust Management in Social Internet of Things
Oct 04, 2019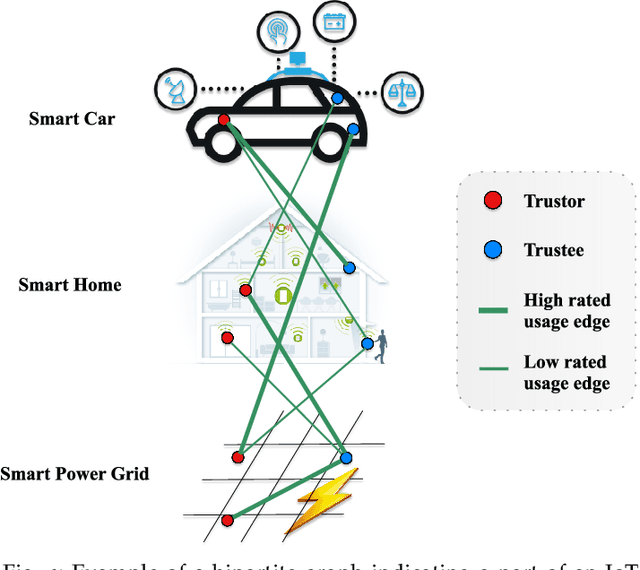
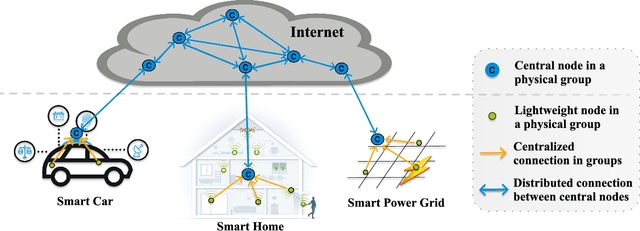
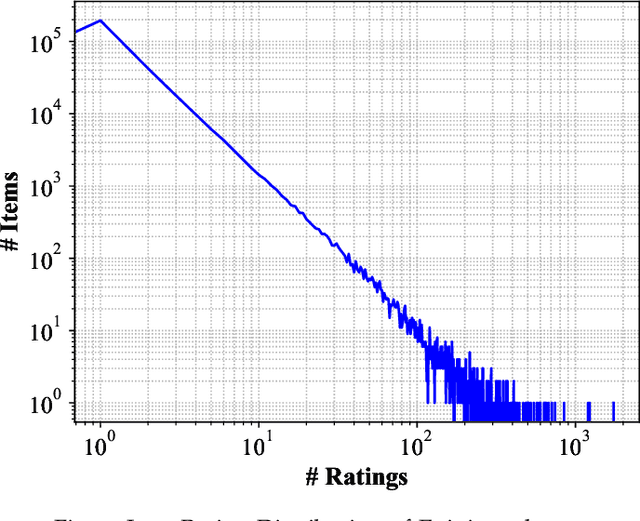
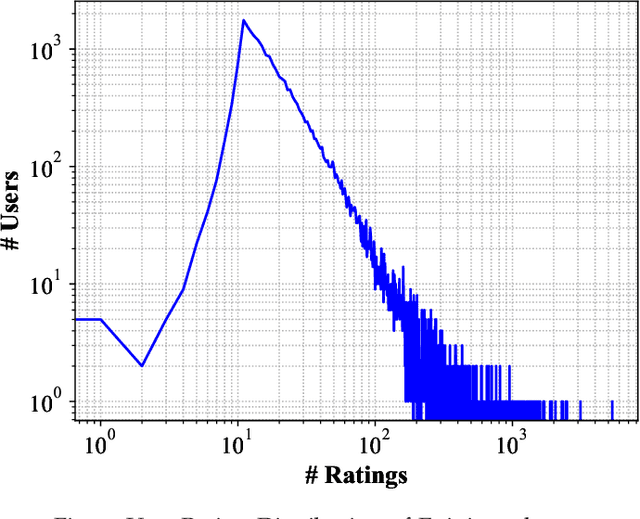
The Social Internet of Things (SIoT), integration of Internet of Things and Social networks paradigms, has been introduced to build a network of smart nodes which are capable of establishing social links. In order to deal with misbehavioral service provider nodes, service requestor nodes must evaluate their trustworthiness levels. In this paper, we propose a novel trust management mechanism in the SIoT to predict the most reliable service provider for a service requestor, that leads to reduce the risk of exposing to malicious nodes. We model an SIoT with a flexible bipartite graph (containing two sets of nodes: service providers and requestors), then build the corresponding social network among service requestor nodes, using Hellinger distance. After that, we develop a social trust model, by using nodes' centrality and similarity measures, to extract behavioral trust between the network nodes. Finally, a matrix factorization technique is designed to extract latent features of SIoT nodes to mitigate the data sparsity and cold start problems. We analyze the effect of parameters in the proposed trust prediction mechanism on prediction accuracy. The results indicate that feedbacks from the neighboring nodes of a specific service requestor with high Hellinger similarity in our mechanism outperforms the best existing methods. We also show that utilizing social trust model, which only considers the similarity measure, significantly improves the accuracy of the prediction mechanism. Furthermore, we evaluate the effectiveness of the proposed trust management system through a real-world SIoT application. Our results demonstrate that the proposed mechanism is resilient to different types of network attacks and it can accurately find the proper service provider with high trustworthiness.
Languages cool as they expand: Allometric scaling and the decreasing need for new words
Dec 11, 2012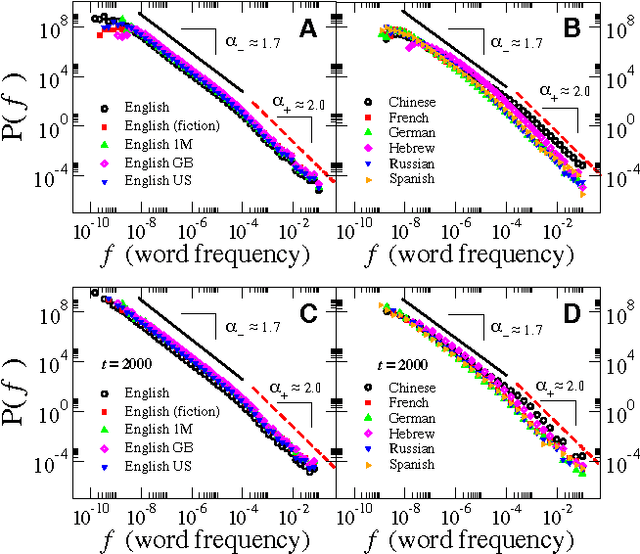

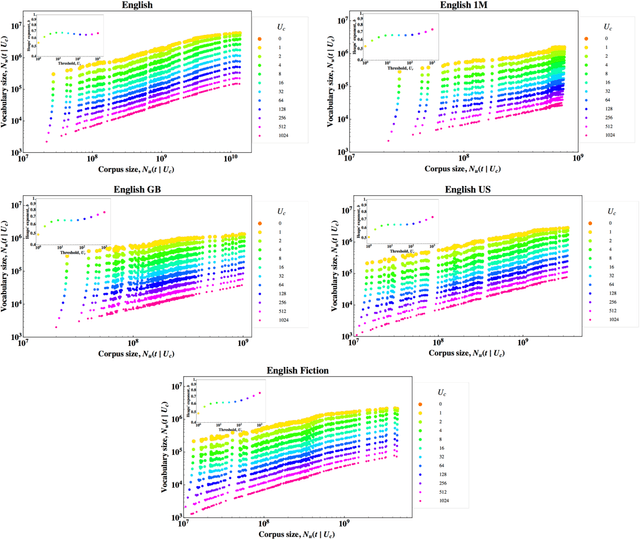
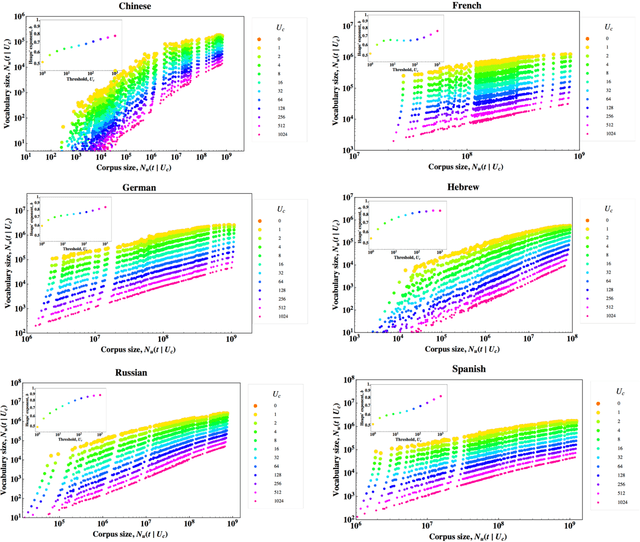
We analyze the occurrence frequencies of over 15 million words recorded in millions of books published during the past two centuries in seven different languages. For all languages and chronological subsets of the data we confirm that two scaling regimes characterize the word frequency distributions, with only the more common words obeying the classic Zipf law. Using corpora of unprecedented size, we test the allometric scaling relation between the corpus size and the vocabulary size of growing languages to demonstrate a decreasing marginal need for new words, a feature that is likely related to the underlying correlations between words. We calculate the annual growth fluctuations of word use which has a decreasing trend as the corpus size increases, indicating a slowdown in linguistic evolution following language expansion. This "cooling pattern" forms the basis of a third statistical regularity, which unlike the Zipf and the Heaps law, is dynamical in nature.
* 9 two-column pages, 7 figures; accepted for publication in Scientific Reports
Statistical Laws Governing Fluctuations in Word Use from Word Birth to Word Death
Feb 15, 2012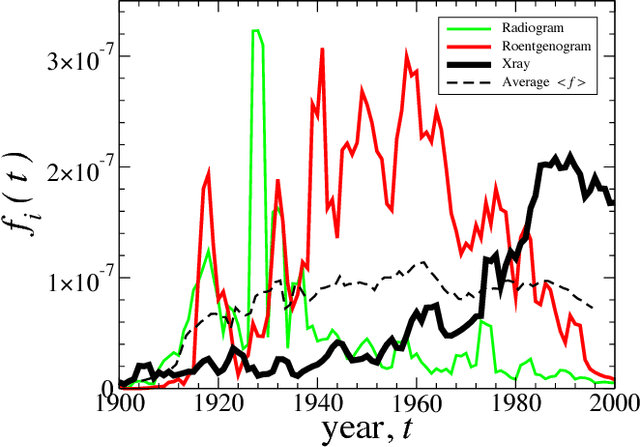
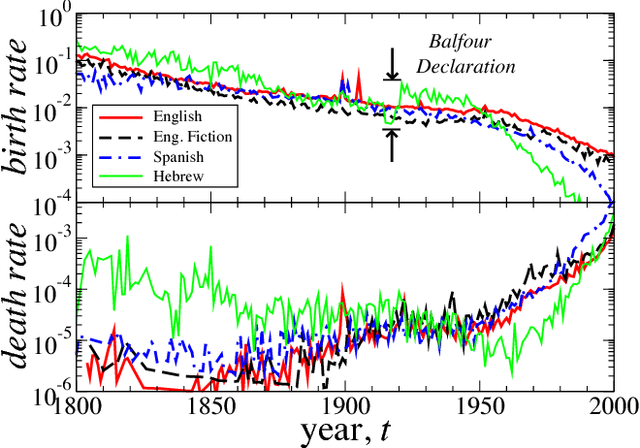
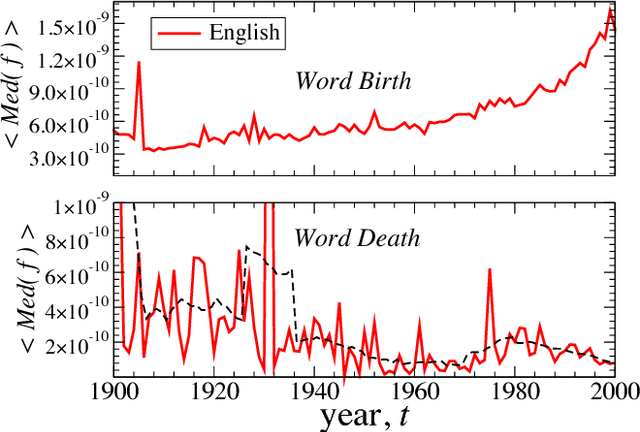
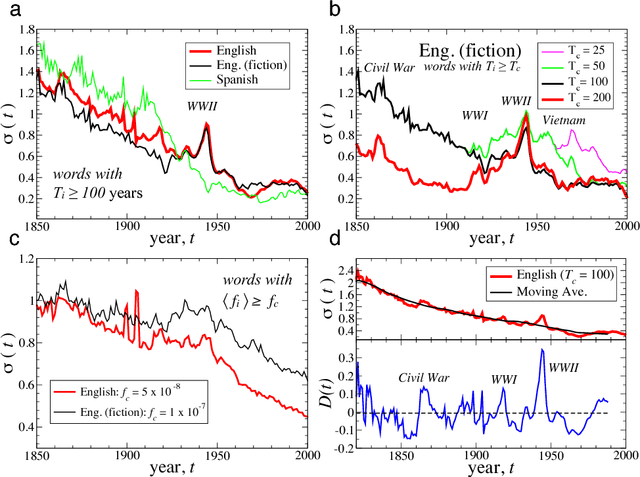
We analyze the dynamic properties of 10^7 words recorded in English, Spanish and Hebrew over the period 1800--2008 in order to gain insight into the coevolution of language and culture. We report language independent patterns useful as benchmarks for theoretical models of language evolution. A significantly decreasing (increasing) trend in the birth (death) rate of words indicates a recent shift in the selection laws governing word use. For new words, we observe a peak in the growth-rate fluctuations around 40 years after introduction, consistent with the typical entry time into standard dictionaries and the human generational timescale. Pronounced changes in the dynamics of language during periods of war shows that word correlations, occurring across time and between words, are largely influenced by coevolutionary social, technological, and political factors. We quantify cultural memory by analyzing the long-term correlations in the use of individual words using detrended fluctuation analysis.
* Version 1: 31 pages, 17 figures, 3 tables. Version 2 is streamlined, eliminates substantial material and incorporates referee comments: 19 pages, 14 figures, 3 tables