 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting column-generation-based matheuristic for learning classification trees
Aug 22, 2023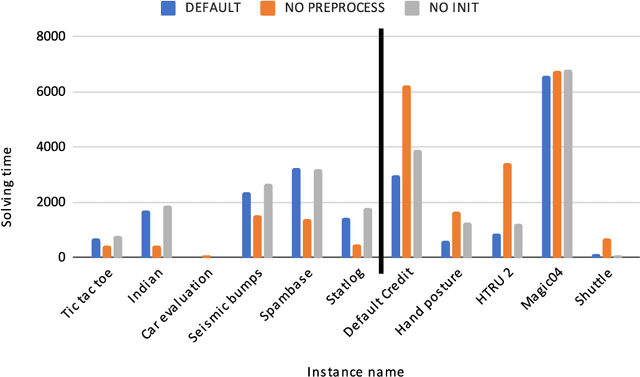
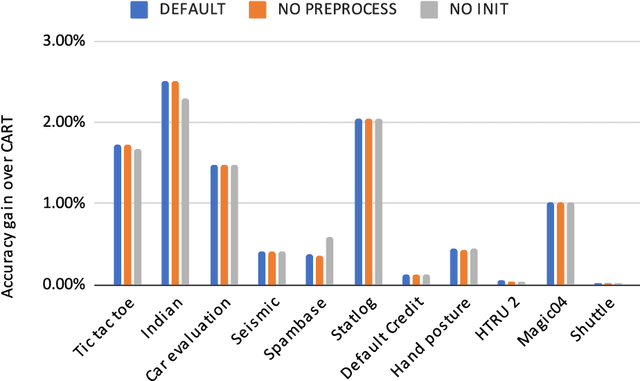
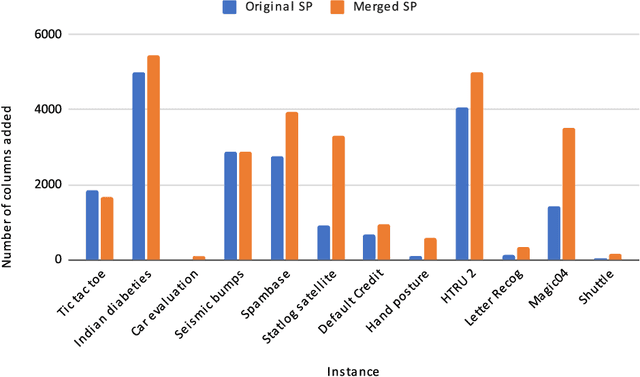
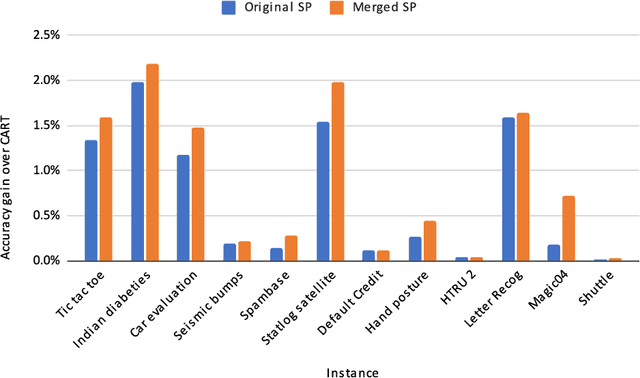
Decision trees are highly interpretable models for solving classification problems in machine learning (ML). The standard ML algorithms for training decision trees are fast but generate suboptimal trees in terms of accuracy. Other discrete optimization models in the literature address the optimality problem but only work well on relatively small datasets. \cite{firat2020column} proposed a column-generation-based heuristic approach for learning decision trees. This approach improves scalability and can work with large datasets. In this paper, we describe improvements to this column generation approach. First, we modify the subproblem model to significantly reduce the number of subproblems in multiclass classification instances. Next, we show that the data-dependent constraints in the master problem are implied, and use them as cutting planes. Furthermore, we describe a separation model to generate data points for which the linear programming relaxation solution violates their corresponding constraints. We conclude by presenting computational results that show that these modifications result in better scalability.
Learning to repeatedly solve routing problems
Dec 15, 2022In the last years, there has been a great interest in machine-learning-based heuristics for solving NP-hard combinatorial optimization problems. The developed methods have shown potential on many optimization problems. In this paper, we present a learned heuristic for the reoptimization of a problem after a minor change in its data. We focus on the case of the capacited vehicle routing problem with static clients (i.e., same client locations) and changed demands. Given the edges of an original solution, the goal is to predict and fix the ones that have a high chance of remaining in an optimal solution after a change of client demands. This partial prediction of the solution reduces the complexity of the problem and speeds up its resolution, while yielding a good quality solution. The proposed approach resulted in solutions with an optimality gap ranging from 0\% to 1.7\% on different benchmark instances within a reasonable computing time.
Explainable prediction of Qcodes for NOTAMs using column generation
Aug 09, 2022
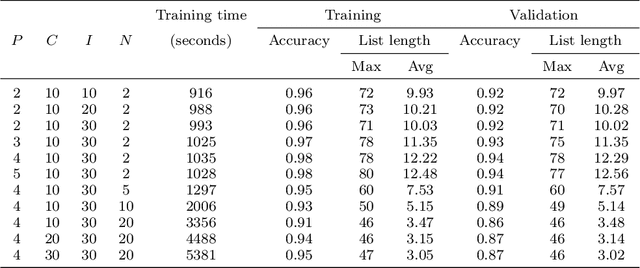
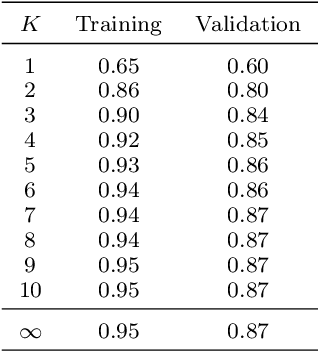
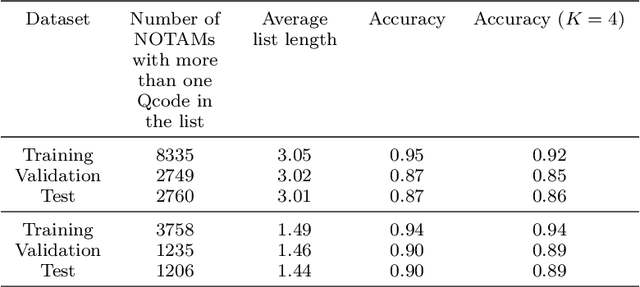
A NOtice To AirMen (NOTAM) contains important flight route related information. To search and filter them, NOTAMs are grouped into categories called QCodes. In this paper, we develop a tool to predict, with some explanations, a Qcode for a NOTAM. We present a way to extend the interpretable binary classification using column generation proposed in Dash, Gunluk, and Wei (2018) to a multiclass text classification method. We describe the techniques used to tackle the issues related to one vs-rest classification, such as multiple outputs and class imbalances. Furthermore, we introduce some heuristics, including the use of a CP-SAT solver for the subproblems, to reduce the training time. Finally, we show that our approach compares favorably with state-of-the-art machine learning algorithms like Linear SVM and small neural networks while adding the needed interpretability component.
Machine-learning-based arc selection for constrained shortest path problems in column generation
Jan 07, 2022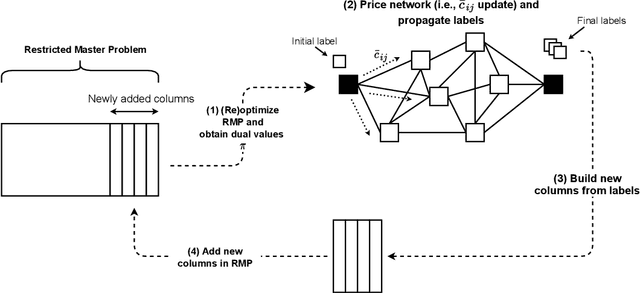


Column generation is an iterative method used to solve a variety of optimization problems. It decomposes the problem into two parts: a master problem, and one or more pricing problems (PP). The total computing time taken by the method is divided between these two parts. In routing or scheduling applications, the problems are mostly defined on a network, and the PP is usually an NP-hard shortest path problem with resource constraints. In this work, we propose a new heuristic pricing algorithm based on machine learning. By taking advantage of the data collected during previous executions, the objective is to reduce the size of the network and accelerate the PP, keeping only the arcs that have a high chance to be part of the linear relaxation solution. The method has been applied to two specific problems: the vehicle and crew scheduling problem in public transit and the vehicle routing problem with time windows. Reductions in computational time of up to 40% can be obtained.
Predicting the probability distribution of bus travel time to move towards reliable planning of public transport services
Feb 03, 2021
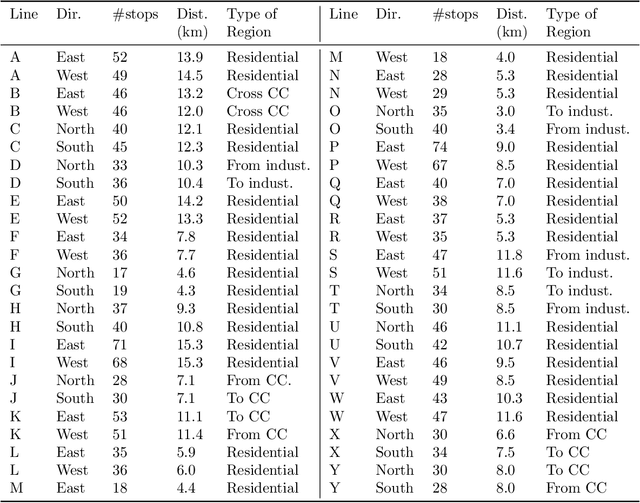
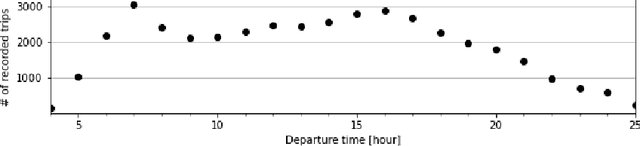
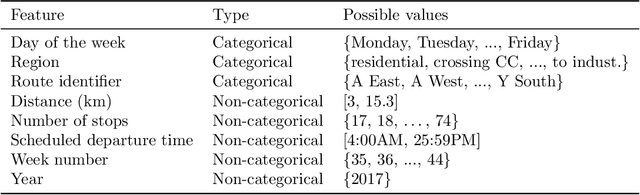
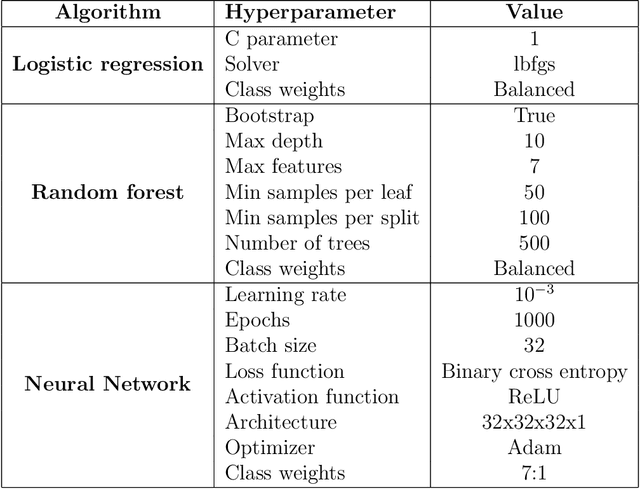
An important aspect of the quality of a public transport service is its reliability, which is defined as the invariability of the service attributes. Preventive measures taken during planning can reduce risks of unreliability throughout operations. In order to tackle reliability during the service planning phase, a key piece of information is the long-term prediction of the density of the travel time, which conveys the uncertainty of travel times. We introduce a reliable approach to one of the problems of service planning in public transport, namely the Multiple Depot Vehicle Scheduling Problem (MDVSP), which takes as input a set of trips and the probability density function (p.d.f.) of the travel time of each trip in order to output delay-tolerant vehicle schedules. This work empirically compares probabilistic models for the prediction of the conditional p.d.f. of the travel time, as a first step towards reliable MDVSP solutions. Two types of probabilistic models, namely similarity-based density estimation models and a smoothed Logistic Regression for probabilistic classification model, are compared on a dataset of more than 41,000 trips and 50 bus routes of the city of Montr\'eal. The result of a vast majority of probabilistic models outperforms that of a Random Forests model, which is not inherently probabilistic, thus highlighting the added value of modeling the conditional p.d.f. of the travel time with probabilistic models. A similarity-based density estimation model using a $k$ Nearest Neighbors method and a Kernel Density Estimation predicted the best estimate of the true conditional p.d.f. on this dataset.