 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Berkelmans-Pries Feature Importance Method: A Generic Measure of Informativeness of Features
Jan 11, 2023Over the past few years, the use of machine learning models has emerged as a generic and powerful means for prediction purposes. At the same time, there is a growing demand for interpretability of prediction models. To determine which features of a dataset are important to predict a target variable $Y$, a Feature Importance (FI) method can be used. By quantifying how important each feature is for predicting $Y$, irrelevant features can be identified and removed, which could increase the speed and accuracy of a model, and moreover, important features can be discovered, which could lead to valuable insights. A major problem with evaluating FI methods, is that the ground truth FI is often unknown. As a consequence, existing FI methods do not give the exact correct FI values. This is one of the many reasons why it can be hard to properly interpret the results of an FI method. Motivated by this, we introduce a new global approach named the Berkelmans-Pries FI method, which is based on a combination of Shapley values and the Berkelmans-Pries dependency function. We prove that our method has many useful properties, and accurately predicts the correct FI values for several cases where the ground truth FI can be derived in an exact manner. We experimentally show for a large collection of FI methods (468) that existing methods do not have the same useful properties. This shows that the Berkelmans-Pries FI method is a highly valuable tool for analyzing datasets with complex interdependencies.
The BP Dependency Function: a Generic Measure of Dependence between Random Variables
Mar 23, 2022
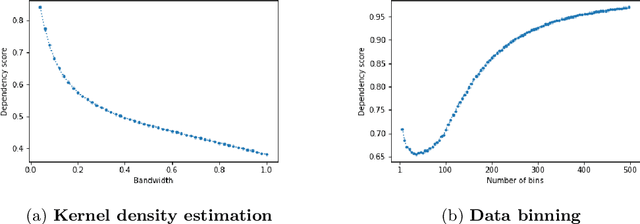
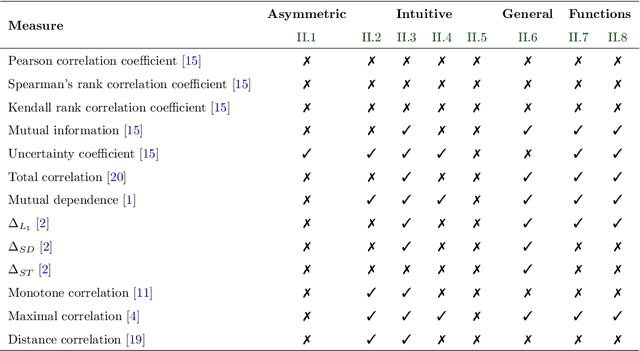
Measuring and quantifying dependencies between random variables (RV's) can give critical insights into a data-set. Typical questions are: `Do underlying relationships exist?', `Are some variables redundant?', and `Is some target variable $Y$ highly or weakly dependent on variable $X$?' Interestingly, despite the evident need for a general-purpose measure of dependency between RV's, common practice of data analysis is that most data analysts use the Pearson correlation coefficient (PCC) to quantify dependence between RV's, while it is well-recognized that the PCC is essentially a measure for linear dependency only. Although many attempts have been made to define more generic dependency measures, there is yet no consensus on a standard, general-purpose dependency function. In fact, several ideal properties of a dependency function have been proposed, but without much argumentation. Motivated by this, in this paper we will discuss and revise the list of desired properties and propose a new dependency function that meets all these requirements. This general-purpose dependency function provides data analysts a powerful means to quantify the level of dependence between variables. To this end, we also provide Python code to determine the dependency function for use in practice.