 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Active Inference
Jan 28, 2026Optimal control of complex environments with robotic systems faces two complementary and intertwined challenges: efficient organization of sensory state information and far-sighted action planning. Because the reinforcement learning framework addresses only the latter, it tends to deliver sample-inefficient solutions. Active inference is the state-of-the-art process theory that explains how biological brains handle this dual problem. However, its applications to artificial intelligence have thus far been limited to extensions of existing model-based approaches. We present a formal abstraction of reinforcement learning algorithms that spans model-based, distributional, and model-free approaches. This abstraction seamlessly integrates active inference into the distributional reinforcement learning framework, making its performance advantages accessible without transition dynamics modeling.
Improving Plasticity in Non-stationary Reinforcement Learning with Evidential Proximal Policy Optimization
Mar 03, 2025On-policy reinforcement learning algorithms use the most recently learned policy to interact with the environment and update it using the latest gathered trajectories, making them well-suited for adapting to non-stationary environments where dynamics change over time. However, previous studies show that they struggle to maintain plasticity$\unicode{x2013}$the ability of neural networks to adjust their synaptic connections$\unicode{x2013}$with overfitting identified as the primary cause. To address this, we present the first application of evidential learning in an on-policy reinforcement learning setting: $\textit{Evidential Proximal Policy Optimization (EPPO)}$. EPPO incorporates all sources of error in the critic network's approximation$\unicode{x2013}$i.e., the baseline function in advantage calculation$\unicode{x2013}$by modeling the epistemic and aleatoric uncertainty contributions to the approximation's total variance. We achieve this by using an evidential neural network, which serves as a regularizer to prevent overfitting. The resulting probabilistic interpretation of the advantage function enables optimistic exploration, thus maintaining the plasticity. Through experiments on non-stationary continuous control tasks, where the environment dynamics change at regular intervals, we demonstrate that EPPO outperforms state-of-the-art on-policy reinforcement learning variants in both task-specific and overall return.
EdVAE: Mitigating Codebook Collapse with Evidential Discrete Variational Autoencoders
Oct 09, 2023Codebook collapse is a common problem in training deep generative models with discrete representation spaces like Vector Quantized Variational Autoencoders (VQ-VAEs). We observe that the same problem arises for the alternatively designed discrete variational autoencoders (dVAEs) whose encoder directly learns a distribution over the codebook embeddings to represent the data. We hypothesize that using the softmax function to obtain a probability distribution causes the codebook collapse by assigning overconfident probabilities to the best matching codebook elements. In this paper, we propose a novel way to incorporate evidential deep learning (EDL) instead of softmax to combat the codebook collapse problem of dVAE. We evidentially monitor the significance of attaining the probability distribution over the codebook embeddings, in contrast to softmax usage. Our experiments using various datasets show that our model, called EdVAE, mitigates codebook collapse while improving the reconstruction performance, and enhances the codebook usage compared to dVAE and VQ-VAE based models.
ProtoDiffusion: Classifier-Free Diffusion Guidance with Prototype Learning
Jul 04, 2023



Diffusion models are generative models that have shown significant advantages compared to other generative models in terms of higher generation quality and more stable training. However, the computational need for training diffusion models is considerably increased. In this work, we incorporate prototype learning into diffusion models to achieve high generation quality faster than the original diffusion model. Instead of randomly initialized class embeddings, we use separately learned class prototypes as the conditioning information to guide the diffusion process. We observe that our method, called ProtoDiffusion, achieves better performance in the early stages of training compared to the baseline method, signifying that using the learned prototypes shortens the training time. We demonstrate the performance of ProtoDiffusion using various datasets and experimental settings, achieving the best performance in shorter times across all settings.
Textile Pattern Generation Using Diffusion Models
Apr 02, 2023



The problem of text-guided image generation is a complex task in Computer Vision, with various applications, including creating visually appealing artwork and realistic product images. One popular solution widely used for this task is the diffusion model, a generative model that generates images through an iterative process. Although diffusion models have demonstrated promising results for various image generation tasks, they may only sometimes produce satisfactory results when applied to more specific domains, such as the generation of textile patterns based on text guidance. This study presents a fine-tuned diffusion model specifically trained for textile pattern generation by text guidance to address this issue. The study involves the collection of various textile pattern images and their captioning with the help of another AI model. The fine-tuned diffusion model is trained with this newly created dataset, and its results are compared with the baseline models visually and numerically. The results demonstrate that the proposed fine-tuned diffusion model outperforms the baseline models in terms of pattern quality and efficiency in textile pattern generation by text guidance. This study presents a promising solution to the problem of text-guided textile pattern generation and has the potential to simplify the design process within the textile industry.
Exploring DeshuffleGANs in Self-Supervised Generative Adversarial Networks
Nov 03, 2020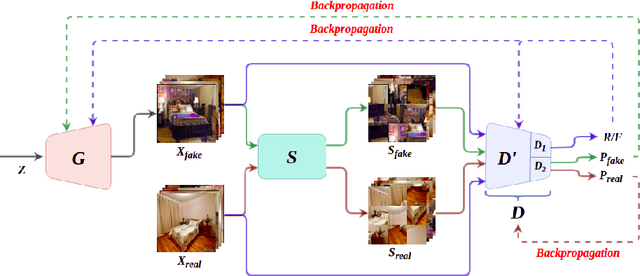


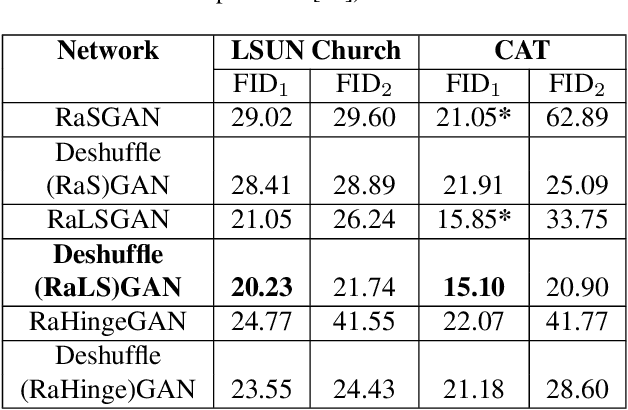
Generative Adversarial Networks (GANs) have become the most used network models towards solving the problem of image generation. In recent years, self-supervised GANs are proposed to aid stabilized GAN training without the catastrophic forgetting problem and to improve the image generation quality without the need for the class labels of the data. However, the generalizability of the self-supervision tasks on different GAN architectures is not studied before. To that end, we extensively analyze the contribution of the deshuffling task of DeshuffleGANs in the generalizability context. We assign the deshuffling task to two different GAN discriminators and study the effects of the deshuffling on both architectures. We also evaluate the performance of DeshuffleGANs on various datasets that are mostly used in GAN benchmarks: LSUN-Bedroom, LSUN-Church, and CelebA-HQ. We show that the DeshuffleGAN obtains the best FID results for LSUN datasets compared to the other self-supervised GANs. Furthermore, we compare the deshuffling with the rotation prediction that is firstly deployed to the GAN training and demonstrate that its contribution exceeds the rotation prediction. Lastly, we show the contribution of the self-supervision tasks to the GAN training on loss landscape and present that the effects of the self-supervision tasks may not be cooperative to the adversarial training in some settings. Our code can be found at https://github.com/gulcinbaykal/DeshuffleGAN.
DeshuffleGAN: A Self-Supervised GAN to Improve Structure Learning
Jun 15, 2020
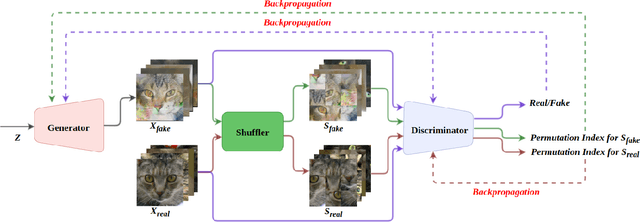

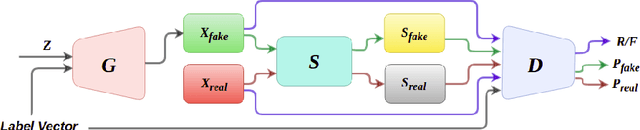
Generative Adversarial Networks (GANs) triggered an increased interest in problem of image generation due to their improved output image quality and versatility for expansion towards new methods. Numerous GAN-based works attempt to improve generation by architectural and loss-based extensions. We argue that one of the crucial points to improve the GAN performance in terms of realism and similarity to the original data distribution is to be able to provide the model with a capability to learn the spatial structure in data. To that end, we propose the DeshuffleGAN to enhance the learning of the discriminator and the generator, via a self-supervision approach. Specifically, we introduce a deshuffling task that solves a puzzle of randomly shuffled image tiles, which in turn helps the DeshuffleGAN learn to increase its expressive capacity for spatial structure and realistic appearance. We provide experimental evidence for the performance improvement in generated images, compared to the baseline methods, which is consistently observed over two different datasets.