 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Darts: User-Friendly Modern Machine Learning for Time Series
Oct 08, 2021We present Darts, a Python machine learning library for time series, with a focus on forecasting. Darts offers a variety of models, from classics such as ARIMA to state-of-the-art deep neural networks. The emphasis of the library is on offering modern machine learning functionalities, such as supporting multidimensional series, meta-learning on multiple series, training on large datasets, incorporating external data, ensembling models, and providing a rich support for probabilistic forecasting. At the same time, great care goes into the API design to make it user-friendly and easy to use. For instance, all models can be used using fit()/predict(), similar to scikit-learn.
Fast Cross-domain Data Augmentation through Neural Sentence Editing
Mar 23, 2020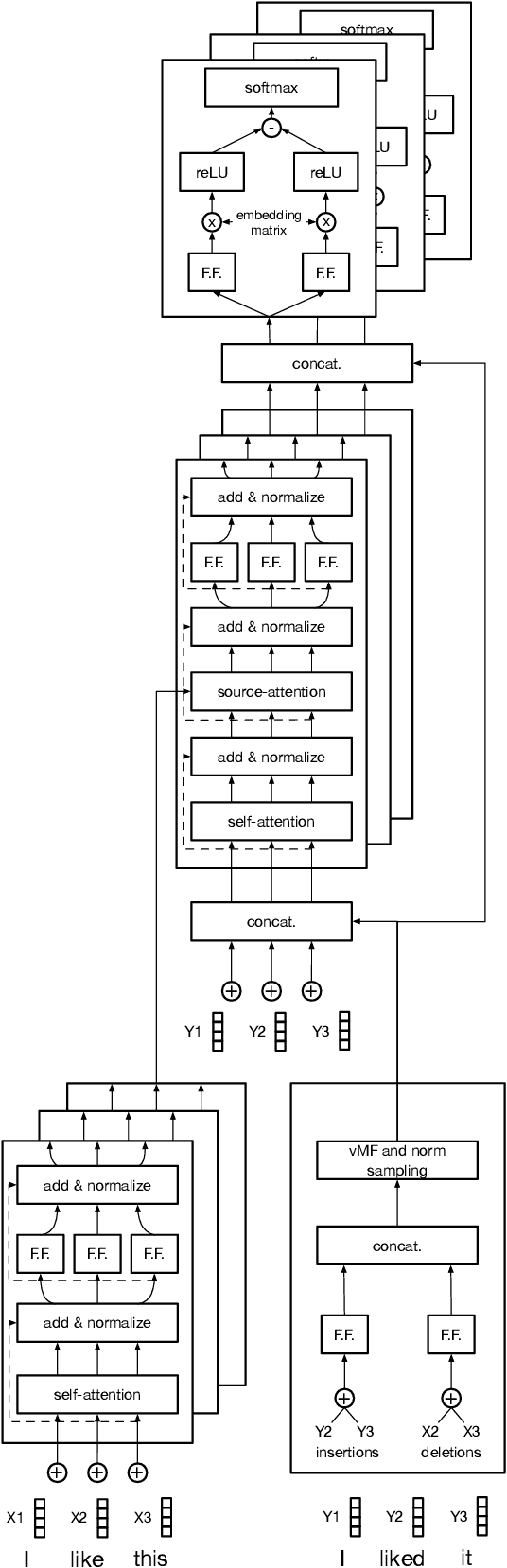

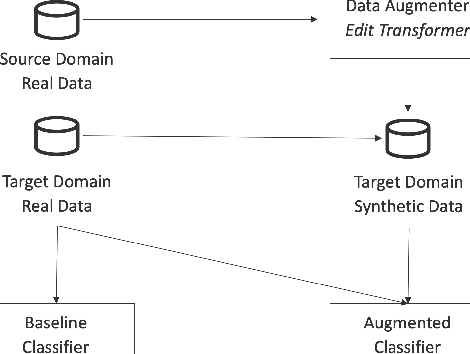
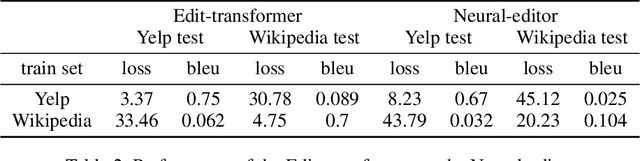
Data augmentation promises to alleviate data scarcity. This is most important in cases where the initial data is in short supply. This is, for existing methods, also where augmenting is the most difficult, as learning the full data distribution is impossible. For natural language, sentence editing offers a solution - relying on small but meaningful changes to the original ones. Learning which changes are meaningful also requires large amounts of training data. We thus aim to learn this in a source domain where data is abundant and apply it in a different, target domain, where data is scarce - cross-domain augmentation. We create the Edit-transformer, a Transformer-based sentence editor that is significantly faster than the state of the art and also works cross-domain. We argue that, due to its structure, the Edit-transformer is better suited for cross-domain environments than its edit-based predecessors. We show this performance gap on the Yelp-Wikipedia domain pairs. Finally, we show that due to this cross-domain performance advantage, the Edit-transformer leads to meaningful performance gains in several downstream tasks.