 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Augmentation for Cross Graph Domain Generalization
Feb 25, 2025Cross-graph node classification, utilizing the abundant labeled nodes from one graph to help classify unlabeled nodes in another graph, can be viewed as a domain generalization problem of graph neural networks (GNNs) due to the structure shift commonly appearing among various graphs. Nevertheless, current endeavors for cross-graph node classification mainly focus on model training. Data augmentation approaches, a simple and easy-to-implement domain generalization technique, remain under-explored. In this paper, we develop a new graph structure augmentation for the crossgraph domain generalization problem. Specifically, low-weight edgedropping is applied to remove potential noise edges that may hinder the generalization ability of GNNs, stimulating the GNNs to capture the essential invariant information underlying different structures. Meanwhile, clustering-based edge-adding is proposed to generate invariant structures based on the node features from the same distribution. Consequently, with these augmentation techniques, the GNNs can maintain the domain invariant structure information that can improve the generalization ability. The experiments on out-ofdistribution citation network datasets verify our method achieves state-of-the-art performance among conventional augmentations.
GraphTTA: Test Time Adaptation on Graph Neural Networks
Aug 19, 2022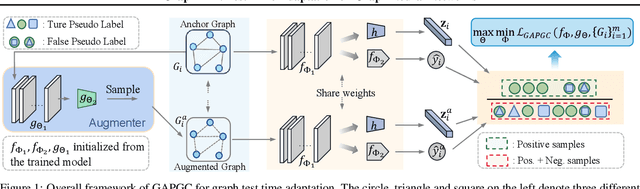
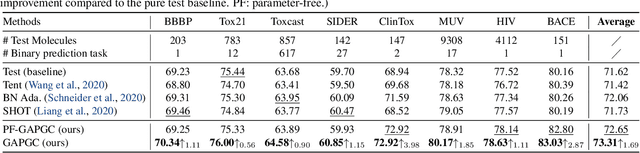
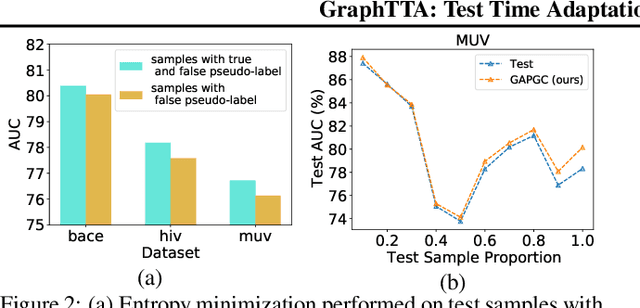

Recently, test time adaptation (TTA) has attracted increasing attention due to its power of handling the distribution shift issue in the real world. Unlike what has been developed for convolutional neural networks (CNNs) for image data, TTA is less explored for Graph Neural Networks (GNNs). There is still a lack of efficient algorithms tailored for graphs with irregular structures. In this paper, we present a novel test time adaptation strategy named Graph Adversarial Pseudo Group Contrast (GAPGC), for graph neural networks TTA, to better adapt to the Out Of Distribution (OOD) test data. Specifically, GAPGC employs a contrastive learning variant as a self-supervised task during TTA, equipped with Adversarial Learnable Augmenter and Group Pseudo-Positive Samples to enhance the relevance between the self-supervised task and the main task, boosting the performance of the main task. Furthermore, we provide theoretical evidence that GAPGC can extract minimal sufficient information for the main task from information theory perspective. Extensive experiments on molecular scaffold OOD dataset demonstrated that the proposed approach achieves state-of-the-art performance on GNNs.
Preventing Over-Smoothing for Hypergraph Neural Networks
Mar 31, 2022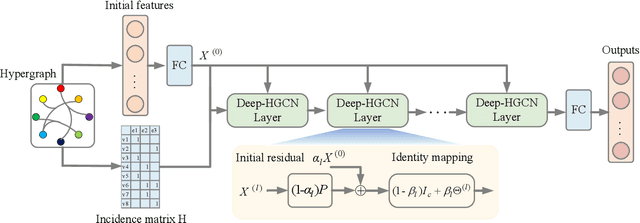
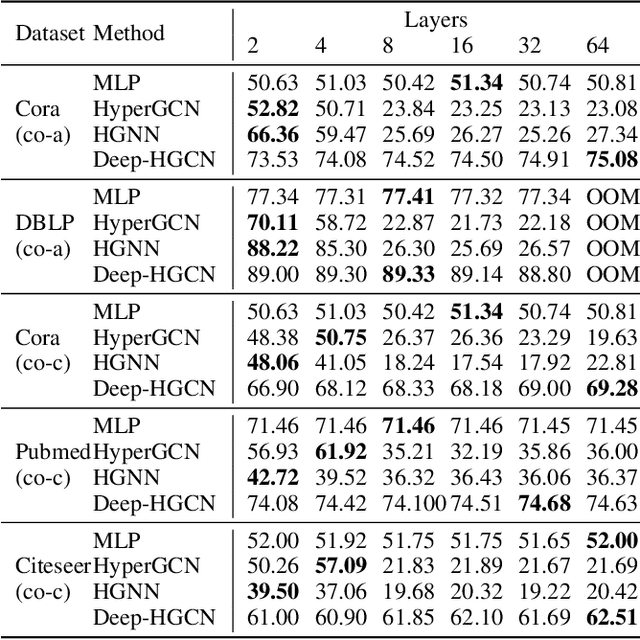
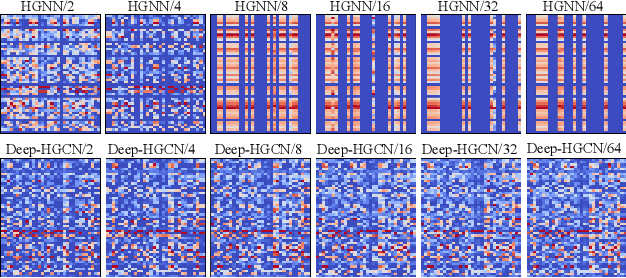
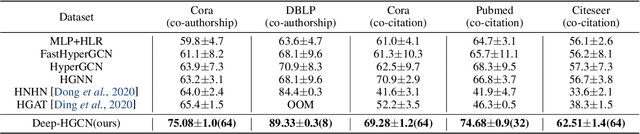
In recent years, hypergraph learning has attracted great attention due to its capacity in representing complex and high-order relationships. However, current neural network approaches designed for hypergraphs are mostly shallow, thus limiting their ability to extract information from high-order neighbors. In this paper, we show both theoretically and empirically, that the performance of hypergraph neural networks does not improve as the number of layers increases, which is known as the over-smoothing problem. To tackle this issue, we develop a new deep hypergraph convolutional network called Deep-HGCN, which can maintain the heterogeneity of node representation in deep layers. Specifically, we prove that a $k$-layer Deep-HGCN simulates a polynomial filter of order $k$ with arbitrary coefficients, which can relieve the problem of over-smoothing. Experimental results on various datasets demonstrate the superior performance of the proposed model comparing to the state-of-the-art hypergraph learning approaches.