 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Trustworthy Video Summarization Algorithm Through a Mixture of LoRA Experts
Mar 08, 2025With the exponential growth of user-generated content on video-sharing platforms, the challenge of facilitating efficient searching and browsing of videos has garnered significant attention. To enhance users' ability to swiftly locate and review pertinent videos, the creation of concise and informative video summaries has become increasingly important. Video-llama is an effective tool for generating video summarization, but it cannot effectively unify and optimize the modeling of temporal and spatial features and requires a lot of computational resources and time. Therefore, we propose MiLoRA-ViSum to more efficiently capture complex temporal dynamics and spatial relationships inherent in video data and to control the number of parameters for training. By extending traditional Low-Rank Adaptation (LoRA) into a sophisticated mixture-of-experts paradigm, MiLoRA-ViSum incorporates a dual temporal-spatial adaptation mechanism tailored specifically for video summarization tasks. This approach dynamically integrates specialized LoRA experts, each fine-tuned to address distinct temporal or spatial dimensions. Extensive evaluations of the VideoXum and ActivityNet datasets demonstrate that MiLoRA-ViSum achieves the best summarization performance compared to state-of-the-art models, while maintaining significantly lower computational costs. The proposed mixture-of-experts strategy, combined with the dual adaptation mechanism, highlights the model's potential to enhance video summarization capabilities, particularly in large-scale applications requiring both efficiency and precision.
UAMD-Net: A Unified Adaptive Multimodal Neural Network for Dense Depth Completion
Apr 16, 2022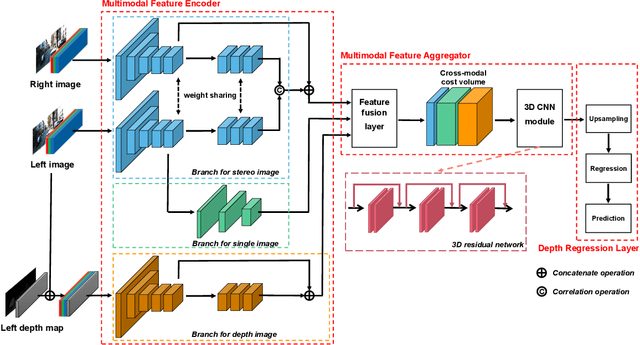
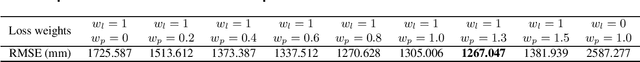

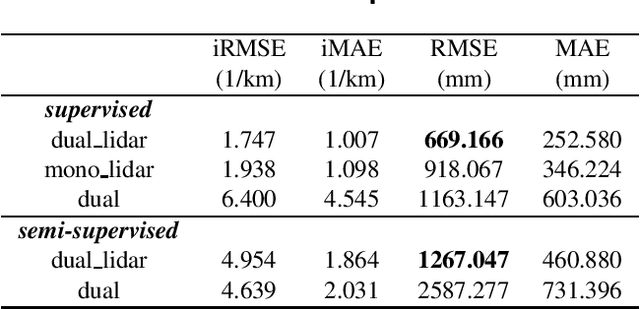
Depth prediction is a critical problem in robotics applications especially autonomous driving. Generally, depth prediction based on binocular stereo matching and fusion of monocular image and laser point cloud are two mainstream methods. However, the former usually suffers from overfitting while building cost volume, and the latter has a limited generalization due to the lack of geometric constraint. To solve these problems, we propose a novel multimodal neural network, namely UAMD-Net, for dense depth completion based on fusion of binocular stereo matching and the weak constrain from the sparse point clouds. Specifically, the sparse point clouds are converted to sparse depth map and sent to the multimodal feature encoder (MFE) with binocular image, constructing a cross-modal cost volume. Then, it will be further processed by the multimodal feature aggregator (MFA) and the depth regression layer. Furthermore, the existing multimodal methods ignore the problem of modal dependence, that is, the network will not work when a certain modal input has a problem. Therefore, we propose a new training strategy called Modal-dropout which enables the network to be adaptively trained with multiple modal inputs and inference with specific modal inputs. Benefiting from the flexible network structure and adaptive training method, our proposed network can realize unified training under various modal input conditions. Comprehensive experiments conducted on KITTI depth completion benchmark demonstrate that our method produces robust results and outperforms other state-of-the-art methods.