 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Ratio-Based Trust Regions for Policy Optimization in Multi-Agent Reinforcement Learning
May 09, 2026Centralized training with decentralized execution (CTDE) is a standard framework for cooperative multi-agent policy-gradient reinforcement learning, allowing agents to learn from joint information while acting from local observations. Ratio-based trust-region methods such as Multi-Agent Proximal Policy Optimization (MAPPO) and Multi-Agent Simple Policy Optimization (MASPO) update decentralized actors using per-agent probability ratios weighted by joint advantage estimates. Teammate non-stationarity increases the variance of these advantages, which in turn increases the variance in the local ratio updates. This exposes two method-specific failure modes: MAPPO's additive clipping removes gradients for outlier samples and weakens recovery from policy drift, while MASPO's soft quadratic penalty can allow probability collapse. We introduce Multi-Agent Ratio Symmetry (MARS), a novel policy optimization objective that replaces these additive ratio-based trust-region mechanisms with a multiplicatively symmetric geometric barrier. MARS preserves corrective gradients while assigning unbounded cost as probability ratios approach zero. Across 47 tasks spanning eight multi-agent environments, including novel JAX benchmarks PaxMen and AeroJAX, MARS matches or exceeds MAPPO and MASPO in aggregate environment-level performance. Ablations show that these gains arise from the geometry of the symmetric barrier rather than from flexible trust-region boundaries alone.
Probabilistic Semantic Retrieval for Surveillance Videos with Activity Graphs
Aug 22, 2018
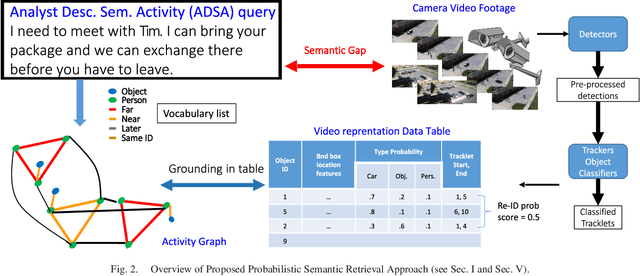
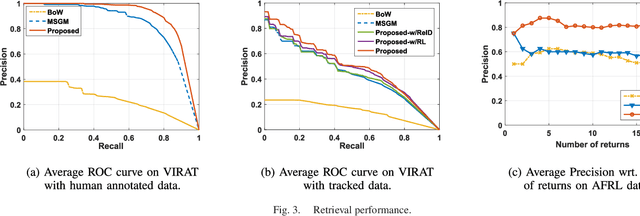

We present a novel framework for finding complex activities matching user-described queries in cluttered surveillance videos. The wide diversity of queries coupled with unavailability of annotated activity data limits our ability to train activity models. To bridge the semantic gap we propose to let users describe an activity as a semantic graph with object attributes and inter-object relationships associated with nodes and edges, respectively. We learn node/edge-level visual predictors during training and, at test-time, propose to retrieve activity by identifying likely locations that match the semantic graph. We formulate a novel CRF based probabilistic activity localization objective that accounts for mis-detections, mis-classifications and track-losses, and outputs a likelihood score for a candidate grounded location of the query in the video. We seek groundings that maximize overall precision and recall. To handle the combinatorial search over all high-probability groundings, we propose a highest precision subgraph matching algorithm. Our method outperforms existing retrieval methods on benchmarked datasets.