 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Semantic Retrieval for Surveillance Videos with Activity Graphs
Paper and Code
Aug 22, 2018
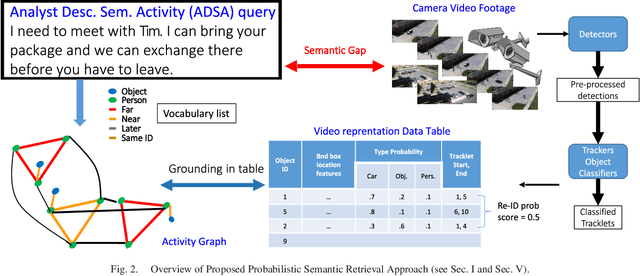
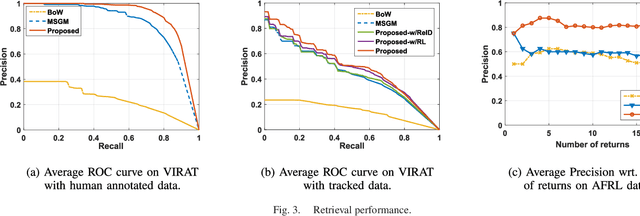

We present a novel framework for finding complex activities matching user-described queries in cluttered surveillance videos. The wide diversity of queries coupled with unavailability of annotated activity data limits our ability to train activity models. To bridge the semantic gap we propose to let users describe an activity as a semantic graph with object attributes and inter-object relationships associated with nodes and edges, respectively. We learn node/edge-level visual predictors during training and, at test-time, propose to retrieve activity by identifying likely locations that match the semantic graph. We formulate a novel CRF based probabilistic activity localization objective that accounts for mis-detections, mis-classifications and track-losses, and outputs a likelihood score for a candidate grounded location of the query in the video. We seek groundings that maximize overall precision and recall. To handle the combinatorial search over all high-probability groundings, we propose a highest precision subgraph matching algorithm. Our method outperforms existing retrieval methods on benchmarked datasets.